Preface
2-9 챕터에서는 DNN 을 위한 supervised learning 을 하는 방법에 대해 공부하였다. 하지만 기존의 챕터에서는 입력과 출력을 연결하는 하나의 방법인 fully-connected layers에 대해서만 다루었다. 챕터 10-13 에서는 주로 이미지 프로세싱에 사용되는 sparse connections, shared weights 그리고 parallel processing paths 등을 포함하는 더 특별한 컴포넌트들을 소개한다.
이미지는 특별한 네트워크 구조를 필요로하는 3가지 특성이 있다.
- 이미지는 고차원이다. 분류 문제에 사용되는 이미지들은 보통 224 224 (=150,528) 의 크기를 갖는다. 보통 hidden layer의 크기는 입력의 크기보다 큰데 둘이 같다고 쳐고 하나의 layer의 크기는 에 해당한다. 이는 필요한 데이터, 메모리, 계산상에서 문제가 발생한다.
- 서로 근처에 있는 이미지 픽셀들은 통계적으로 비슷하다. 하지만 fc layer 는 “근처”에 있는 픽셀들을 따로 다루지 않고 이미지에 있는 모든 픽셀들의 사이를 동일하게 다룬다.
- 이미지는 기하학적인 변형 (geometric transforms) 을 하더라도 해당 이미지의 의미는 변하지 않는다. 예를 들어 어떤 나무 이미지가 있을 때 왼쪽으로 4픽셀 이동해도 여전히 나무인 이미지이다. 하지만 이러한 4픽셀의 이동은 입력을 완전히 바꾸어 놓는다. 따라서 fc layer 는 이러한 작은 변화라도 모든 패턴을 학습해야하기 때문에 전혀 효율적인 모델이 아니다.
Convolution layers 는 전체 이미지가 공유하는 파라미터들로 각 이미지의 local region을 독립적으로 프로세싱한다. 이는 주변의 픽셀들의 spatial relationship 을 이용하여 fc layer보다 더 적은 파라미터를 사용하며, 모든 이미지에 속해 있는 각각의 픽셀들에 대해 다시 학습할 필요가 없다. convolutional layers를 주로 갖는 네트워크를 convolutional neural network, CNN 이라고 한다.
10.1. Invariance and Equivariance
앞서 이미지가 transformation 에 대해 안정적이라는 (의미가 변하지 않음) 사실을 보았다. 본 섹션에선 위 아이디어를 수학적으로 명확히 짚고 넘어가고자 한다.
이미지, 의 함수, 는 transform, 에 대해 다음을 만족하면 invariant 하다고 한다.

한 마디로 입력 이미지 나 transformed 된 이미지, 가 (예를 들어,) 이미지 분류에서 같은 결과를 내야한다는 것이다. (Fig. 10.1.) ((a), b) 나 “mountain” 으로 같아야함. )

모델 는 어떤 이미지를 움직이던 (translated), 돌리던 (rotated), 뒤집던 (flipped) 혹은 와핑 (warpping) 을 하던 원본 이미지와 같은 objects 를 포함한 것으로 인식해야한다.
또한 아래 식을 만족하면 모델, 는 transform, 에 대하여 equivariant 혹은 covariant 하다고 한다.

한 마디로, transform을 한 이미지를 모델에 넣은 결과와 원본 이미지를 넣고 transform을 한 결과가 같아야한다는 것이다. Fig. 10.1. 을 보면 c) 는 원본 이미지, , e) 는 를 입력으로 받은 segmentation model의 결과, , d)는 transoformed image, , f) 는 이다.
위 예시의 segmentation model 인 는 equivariant 혹은 covariant 하다. Eq. 10.2. 의 좌변은 e) → f), 우변은 d) → f) 로 둘이 같기 때문이다.
10.2. Convolutional Networks d for 1D Inputs
CNN은 translation 에 equivariant 한 convolution layers의 series로 이루어져있다. 또한 보통 translation 에 partially invariance 하도록 유도하는 pooling mechanism을 포함한다. 이를 설명하기 위해 2D에 앞서 먼저 1D CNN을 다루어 이를 명확히 하고자 한다.
10.2.1. 1D Convolution Operation
1D 에서 convolution operation 은 input vector 를 output vector, 로 각 output, 가 input의 주변 값들의 weighted sum으로 맵핑하는 함수이다. 모든 입력의 position에서 같은 weights가 사용되고 이러한 weights 들을 종합적으로 convolution kernel, kernel 혹은 filter 라고 부른다. input 들이 weighted 되고 더해지는 그 “region”을 kernel size 라고 한다. 3의 kernel size를 가지면 아래와 같이 계산이 가능하다.

kernel, 이다. (Fig. 10. 2.).

주목할 점은, convolution 연산은 translation 에 대해서 equivariant 하다는 점이다. 만약 입력, 를 translate 됐다면, 도 역시 같은 방법으로 translated 된다.
10.2.2. Padding
Eq. 10.3. 을 살펴보면 하나의 output, 를 계산하기 위해서는 입력의 현재 위치, 이전 위치들, 다음 위치들의 입력 값들을 weighted sum 해야한다. 이들은 따라서 이전 위치들의 입력 값이 없는 앞에 있는 입력 값들과, 다음 입력 값들이 없는 마지막의 입력 값에 대해서 출력을 어떻게 계산해야하는가? 라는 질문을 던질 수 있다.
이에 대하여 다음과 같은 2가지의 접근법이 있다.
Padding: 입력의 각 끝에 (edges) 새로운 값들을 할당하고 기존에 하던 대로 계산하는 것이다.Zero padding은 입력의 바깥이 (in valid range) 으로 채워져 있다고 가정하는 것이다. (Fig. 10.2. c)) (가장 일반적인 선택)
- 두 번째 방법은 각 바운더리가 circular 하거나 reflect 하다고 가정하는 것이다.
Valid convolution: 계산이 가능한 입력에 대해서만 convolution을 수행한다. 이와 같은 방법은 입력의 edge 부분에 대해서 추가적인 정보를 사용하지 않는다는 장점이 있지만, 입력 크기가 줄어든다는 단점이 있다.
10.2.3. Stride, Kernel Size and Dilation
위 예제에서 각 output, 는 주변 3개의 inputs, 의 weighted sum 임을 공부하였다. 하지만 이는 단지 대단히 많은 convolution operation 함수의 일부분일 뿐이다. convolution operations 들은 stride, kernel size 그리고 dilation rate 에 따라 다양하게 존재한다.
위 예제에서 각 출력의 값을 계산할 때, stride 를 로 하였다. stride의 크기를 보다 더 큰 값으로 하여 kernel을 움직일 수 있다. 만약 stride의 크기를 2로 출력의 크기는 거의 절반이 된다. (Fig. 10.3.a-b)

kernel size 를 크게하면 weighted sum 할 영역 (region)을 넓힐 수 있다. 하지만 보통 convolution 연산을 할 때 가운데 있는 값이 가운데 있게 하기 위해서 kernel size 는 홀수로 하는 것이 국룰이다. kernel size를 키우는 것은 계산할 weights 가 더 많아진다는 단점이 있다. 이러한 점에서 dilated 혹은 atrous convolutions 이라는 개념이 고안된다. 이는 kernel values 들을 간단히 말해서 kernel 의 각 weights 간의 간격을 넓히는 것이다. 각 weights 간의 zeros 의 갯수를 dilation rate 이라고 한다. (Fig. 10.3d)
10.2.4. Convolutional Layers
Convolutional layer 는 입력, 를 빙빙 돌며 출력, 를 계산한다. 그리고 activation function, 을 통과한 값을 activation 으로 사용한다. kernel size=3, stride=1, dilation=0 일 때, hidden unit, 의 값은 아래와 같이 계산된다.
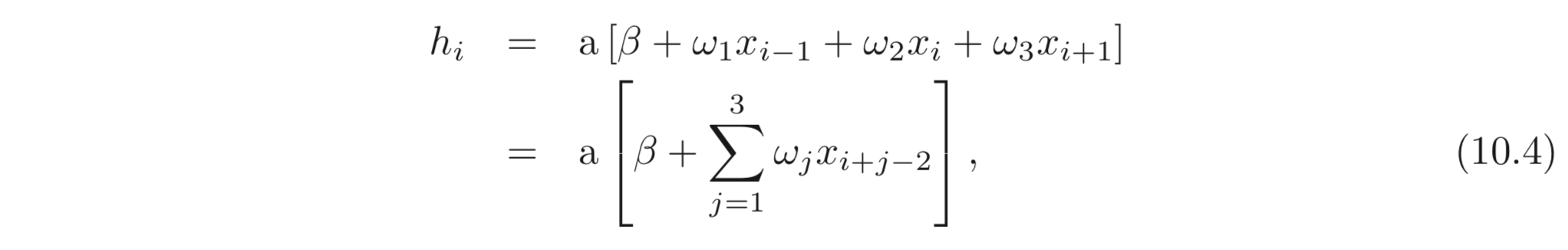
bias, , weights, 은 trainable parameters 이고, zero padding 을 사용하였다. 이는 아래와 같이 hidden unit의 출력을 계산하는 fc-layer의 특별한 케이스이다.

만약, 입력, 에 대하여 출력, 를 내는 모델, fc-layer가 있을 때, 이의 weights, 와 bias, 들의 파라미터의 총 갯수는 개 이다. 반면 convolution layer는 3개의 weights, 1개의 bias 값으로 총 개의 파라미터만을 갖는다.
만약 fc-layer의 weights, 의 값들이 대부분 이고 같은 값들을 갖도록 제한한다면, convolution layer와 똑같은 연산을 하게 된다. (Convoltuion 연산도 Matrix 곱으로 표현할 수 있다는 것이다!!!!!) (Fig. 10.4.)

10.2.5. Channels
하나의 convoltuion layer 만을 사용한다면 각 layer 를 통과할 때마다 정보가 많이 손실된다. 따라서 여러 convolution 연산을 한 번에 하는 것이 일반적이다. 각 convolution 연산은 feature map 혹은 channel 이라고 불리는 hidden variables 들의 set을 생성한다.
Fig. 10.5a-b 는 두 개의 convoltuion layer를 사용하는 예시를 보인다.

첫 번째 kernel 은 , 두 번째 kernel 은 의 결과를 만들어 낸다. 이들은 각각 하나의 channel 을 형성하고 최종적으로 2개의 channels 를 갖는 출력을 얻는다.
보통, Fig. 10.5c 와 같이 입력, 출력 모두 여러 개의 channels 을 갖는 경우가 많다. 만약 입력의 channel이 , kernel size 가 라면 개의 channels 에서 개 만큼의 입력 값들을 weighted sum 해야하므로, kernel의 weight, 와 하나의 bias, 를 갖는다. 따라서 출력 channel, 가 있다면, 최종적으로 하나의 layer 가 가져야할 weight 는 가 되며 bias는 가 된다.
10.2.6. Convolutional Networks and Receptive Fields
챕터 4의 DNN과 마찬가지로 convolution networks 도 sequence of convolution layers 로 나타낼 수있다. 여기서 각 hidden units에 대하여 해당 layer에 입력으로 들어가는 원래 이미지의 영역을 Receptive Field 라고 한다. (see Fig. 10.6.)

각 convolution layer의 kernel size=3 인 CNN을 생각해보자. 첫 번째 layer (Fig. 10.6a) 의 receptive field 의 크기는 3이다. 두 번째 layer (Fig. 10.6b) 에서는 5, 마찬가지로 3번째는 7, 마지막은 9 (원본 입력의 모든 값들) 가 된다.
따라서 layer 가 깊어질 수록 receptive field의 크기가 점차 증가하고 이는 곧, 입력 이미지의 정보가 점진적으로 layer를 거듭할 수록 합쳐진다고 볼 수 있다.
10.2.7. Example: MNIST-1D
이제 앞서 공부한 내용을 바탕으로 MNIST-1D 데이터셋을 학습해보자. 입력, 의 vector 이고, 최종 출력, 이다. 이는 softmax 함수를 통과하여 각 class를 대표하는 확률 값으로 나타내어진다. 여기서는 3개의 hidden layers를 포함하는 모델을 사용한다. (Fig. 10.7.)

Hidden units, 들은 각각 출력 dimensions과 channels 의 크기를 갖는다. 예를 들어 에서 는 출력 dimentsion 을 의미하고, 는 출력 channel을 의미한다. 그리고 마지막 에서 로 넘어가는 지점에서는 를 으로 쭉 펴서 weight, 를 갖는 fc layer 를 사용한 것이다.
vanilla SGD 를 사용하여 100,000 steps 학습하였고, learning rate 은 0.01, batch size 는 100, total data의 수는 4,000개이다. 이렇게 CNN을 이용하여 학습한 결과를 fc layer 만을 사용한 모델과 성능을 비교하였다. CNN은 2,050개, fc network 는 150,185 개의 파라미터를 갖는다. 앞서 언급한 바대로 CNN은 fc network 의 스페셜 케이스라고 볼 수 있다. (Fig. 10.8)

FC network는 CNN 보다 훨씬 많은 파라미터의 수를 가지므로 더 나은 성능을 기대할 수 있다. 두 경우 모두 training set 에 대해서는 완벽하게 학습하였다. 하지만 Test 성능에 대해서는 CNN이 훨씬 좋은 성능을 보인다.
이러한 모순은 비단 파라미터의 갯수 차이만으로 생기는 것은 아니다. (우리는 앞서 overparameterization 에 대해서 더 나은 성능을 기대할 수 있다고 배웠는데..!). 이런 성능의 차이는 우리가 CNN에 inductive bias 를 직접 주입하였기 (embodied inductive bias to CNN) 때문이라고 보는 것이 가장 그럴듯한 설명이다.
무슨 말이냐면, 입력 이미지의 서로 region을 같은 파라미터로 계산하도록 모델의 구조를 설계하여 모델이 그렇게 학습하였다는 의미이다.
FCN은 나무가 약간만 움직여도 이것이 나무라는 사실을 모든 파라미터를 동원하여 움직이기 전의 나무와 움직인 후의 이미지가 같다는 패턴을 학습해야한다.
하지만 CNN은 그냥 설계 자체를 local 하게나마 invariant 할 수 밖에 없도록 설계 했기 때문에 모델이 패턴을 파악하기 더욱 쉬웠을거라는 설명이다.
또 다른 설명으로는 CNN은 “이미지의 픽셀간은 서로 밀접한 연관이 있다.” 라는 inductive bias 를 토대로 설계 되었기 때문에 FCN 으로 학습할 수 있는 대부분의 solution에 대하여 regularizer 로 동작했다. 라는 설명도 타당하다고 볼 수 있다.
10.3. Convolutional Networks for 2D Inputs
1D-CNN은 주가 데이터, 오디오, 텍스트에 사용될 수 있지만 주로 2D 이미지를 프로세싱하는데 주로 사용된다. 따라서 이제 kernel 은 와 같은 2D 의 shape 을 갖는다. Kernel, 는 2d 입력의 값, 에 대하여 아래와 같이 hidden unit을 계산한다.

은 kernel 의 각 weight 값이다. 이 또한 역시 간단한 weighted sum 으로 구현된다. (Fig. 10.9)

보통 입력은 3개의 channel을 갖는 2D signal인, RGB 이미지이다. (Fig. 10.10)

kernel size를 , 입력 channel을 이라고 하면 weights의 크기는 이다. kernel size=3, 이고 입력 channel은 3이므로 weights, 이다. 여러 channel을 갖는 출력을 생성하기 위해서는 이와 같은 kernel 을 , output의 channel 수 만큼 사용하면 된다. 그러면 출력의 결과로 3D 의 tensor 가 생성된다.
weights, 의 총 파라미터의 수는 따라서 개가 되며, bias 의 갯수는 개가 된다. (각 kernel 당 하나씩이니께)
10.4. Downsampling and Upsampling
Fig. 10.7 에서 보인 모델은 stride 를 2로 설정함으로 각 layer를 내려갈 때마다 receptive field 가 scailing 했다. 본 섹션에서는 2D input representation 을 scailing down 즉, downsampling 하는 방법에 대해 공부한다. 또한 출력이 이미지일때 유용한 (downsampling 한 결과를 다시 되돌려놓는) upsampling 에 대해서도 공부한다. 마지막으로 각 layer 사이에 channel 수를 조절하는 방법에 대해서도 공부한다. 이는 서로 다른 브랜치를 갖는 네트워크를 합칠 때 유용한다.
10.4.1. Downsampling
Downsampling 에는 크게 3가지의 방법이 있다. 여기서는 가장 널리 사용되는 이미지를 절반으로 줄이는 방법에 대해 본다.

- 각각의 포지션에서 샘플링. fig.10.11a 에서는 각각의 위치에서 좌상단의 값을 샘플링하였다.
Max pooling: 각각의 위치에서 가장 큰 값을 sampling 하는 방법이다. (Fig. 10.11b) 이러한 방법은 모델의 invariant 를 주입할 수 있다.
Mean poolingorAverage pooling입력들을 평균 내는 것이다.
위 3가지 방법 모두 사용할 때 각각의 channel 에 대해서 수행한다. 따라서 입력이 라면 출력은 가 된다.
10.4.2. Upsampling

Upsamplig 을 하는 가장 간단한 방법은 다음과 같다.
- resolution 을 두 배로 늘리고 거기에 값을 복사. (Fig. 10.12a)
Unmax pooling: 기존의 max pooling 을 그대로 복원하는 것. 그러려면 max pooling 전의 정보를 알아야한다. (Fig. 10.12b)
- 각 값들을 interpolation 하는 방법 (Fig. 10.12c)
그리고 마지막으로 Transposed Convolution 이 있다. (Fig. 10.13)

Transpose Convoltuion: 이는 stride=2 를 주어 downsampling 하는 방법을 뒤집은 것이라고 생각해도 좋다. Fig. 10.13a와 Fig. 10.13c 를 비교해보자. 화살표의 방향만 반대로 돌리면 Transposed convoltuion 이다.이와 같은 upsampling 연산을 하는 matrix를 고려한다고 했을 때 단순히 downsampling 하는 matrix를 transpose 하면 된다는 것을 알 수 있다. (Fig. 10.13 b,d) 그래서 이름도..
10.4.3. Changing the number of Channels
결과의 크기 () 를 바꾸는 것을 downsamplng, upsampling 을 통해 공부하였다. 그렇다면, 를 유지하며 channel 의 크기만 바꾸는 것은 어떻게 할 수 있을까? (모델을 설계할 때 많이 필요한 테크닉임. See chapter 11)
이를 위해 Convolution 을 사용할 수 있다. (Fig. 10.14)

이는 각 position, () 에서 channel 에 있는 hidden units 들에 대하여 각각 FC layer를 통과시킨 것과 같은 역할을 한다.
10.5. Applications
본 챕터를 3개의 computer vision applicatios 을 설명하는 것으로 마무리한다.
Image Classification
Object Detection
Semantic Segmentation
10.5.1. Image Classification
대부분의 선구적인 CV 분야의 딥러닝 연구는 ImageNet data를 사용하여 Classficiation task 를 해결하는데 초점이 맞춰져있었다. (Fig. 10.15)

ImageNet 은 개의 training data, 50,000 개의 valication set, 100,000 장의 test 데이터로 구성된다. 그리고 각각의 이미지는 1,000 개의 클래스 중 하나의 label 로 할당돼있다.
ImageNet Competition 에서 사용되던 국룰 이미지 사이즈는 의 RGB 이미지 (3 channel) 이다. 딥러닝 이전의 방법 중 SOTA의 알고리즘이 ImageNet classification 의 test set 에서 top- error-rate 은 였다. 그리고 딱 5년 뒤에 딥러닝 모델이 사람의 성능을 뛰어넘었다.
2012년 AlexNet 은 본 task 에 제대로 동작한 첫 번째 CNN이었다. (Fig. 10.16)

AlexNet 은 의 top-5 test error 를 기록하였고, 의 top-1 error rate 을 기록하였다. 이와 같은 결과는 딥러닝의 가능성을 보여준 사건이었고, 현대의 AI 연구에 박차를 가하였다.
VGG network 도 Image Classficiation 에 초점을 맞춘 모델이다. 의 top-5 error, 의 top-1 error 로 훨씬 나은 성능 향상을 보였다. 해당 모델은 거의 비슷하게 생긴 convolution layer와 max pooling layer 들의 series 로 구성되었다. 그리고 마지막으로는 3개의 FC Layer로 연결 하였다. (Fig. 10.17)

위 모델 모두 data augmentation ,dropout, weight decay 를 사용하여 학습하였다. 물론 다양한 내부적으로 다른 점은 있지만 AlexNet 과 VGGNet 의 차이점은 바로 depth의 차이였다. 이는 depth 가 증가하면 성능도 증가하는 것을 보여준 예이며, depth 가 딥러닝에서 중요한 역할을 한다는 증거가 되었다.
10.5.2. Object Detection
Object Detection 은 이미지에서 여러 개의 objects 들을 identify 하고 localize 하는 것이 목표이다. CNN을 이용한 초기 모델은 You Only Look Once, YOLO 였다. YOLO 모델의 입력은 의 RGB 이미지이다. 먼저 입력으로 들어가면 24 개의 convolution layer 를 통과하며 representation size () 는 줄이며, channels 은 증가시킨다. 모든 convolution layers 를 통과한 최종 shape 은 이다. 이는 flatten 되어 FC layer에 넘겨지고 의 크기의 vector 로 맵핑된다. 그리고 또 다른 FC layer를 통과해 최종 output을 나타낸다.
해당 output 의 값들은 아래와 같은 (Fig. 10.18a) 각각의 크기의 grid에 어떤 class의 object 가 있는지 encoding 한다.

각각의 grid 에 대하여, output vector 는 고정된 갯수의 boxes 를 predict 한다. (Fig. 10.18b) 각각의 box들은 5개의 파라미터로 표현된다. 각각 의 위치, 의 너비, 높이, 그리고, 의 해당 클래스의 confidence 이다. (Fig. 10.18c). confidence 는 예측된 박스와 GT box 간의 오버랩된 부분을 나타낸다.
YOLO는 momentum 이 추가된 optimizer 를 사용했으며, weight decay, dropout 그리고 data augmentation 이 사용되었다. 또한 transfer learning 도 사용되었다. 네트워크는 먼저 ImageNet 으로 pretrained 된 모델을 사용하였다.
network 가 이미지를 받아 출력을 내면, 이를 휴리스틱한 방법으로 불필요한 box들을 제거 하였다. Confidence 가 낮고 같은 object 에 대하여 겹쳐있는 박스들을 제거하여 최종적으로 가장 confidence 한 box만을 남기는 방법을 사용한다.
10.5.3. Semantic Segmentation
Semantic Segmentation 의 목표는 각 픽셀을 classification 하는 것이다. 초기 단계의 semantic segmentation 모델의 구조는 아래와 같다. (Fig. 10.19)

입력은 의 RGB 이미지이고, 출력은 의 각 픽셀의 위치에서 21개의 클래스에 해당하는 확률 분포를 나타내는 이미지이다.
입력을 받는 전체 모델의 왼쪽 절반은 축소된 버전의 VGG 모델이다. 그리고 남은 오른쪽의 모델은 Max Unpooling 과 deconvolution layer로 이루어져있는데, 이는 Transposed Convolution layer 와 동일하다. 마지막 결과 이미지를 생성하기 위해 convoltuion layer를 사용했다.
왼쪽 절반을 보통 encoder 라고 부르고 오른쪽 절반을 decoder 라고 부른다. 따라서 이러한 구조를 갖는 모델을을 Encoder-Decoder Network 라고도 부르고 Hourglass Network 라고도 부른다.
그리고 최종 결과는 YOLO 와 비슷하게 휴리스틱한 방법을 통해 후처리한다. 매 픽셀을 돌며 greedy 하게 각 픽셀들의 class를 결정하는데 이때 주변 픽셀들은 비슷한 class를 가질 것이므로 이들의 connectedness도 고려한다. 그리고 label 이 결정되지 못한 픽셀들에 대해서는 가장 dominate 한 클래스들을 부여한다. (Fig. 10.20)

Uploaded by N2T