Chapter 8 에서는 model 의 performance 를 측정하였고 학습 데이터와 테스트 데이터 간의 큰 성능 차이가 존재한다는 것을 확인했다. 이러한 차이의 원인으로는 다음과 같다. (1) 모델이 학습하는 것은 true underlying function 을 학습하는 것이 아닌 학습 데이터의 확률적 특성 (peculiarities) 을 학습한다. (Overfitting) (2) 학습 데이터가 없는 space 에 대해서 모델이 제약을 받지 않는다. 이로 인해 optimal 한 prediction 을 내지 못한다.
본 챕터에서는 regularization techniques 에 대해서 공부한다. 이는 training, test performance 간의 gap 을 줄이는 methods 들의 집합이다. 엄밀히 말해서, regularization 은 특정한 parameters 를 선택하도록 loss 에 더해지는 explicit 한 loss term 을 의미한다.
우리는 가장 엄밀한 의미에서의 regularization 에서 시작한다. 그리고 SGD 스스로가 특정 솔루션을 선호하는지 보인다. 이는 implicit regularization 으로 알려있다. 다음으로는 test performace 를 증가시킬 수 있는 early stopping, ensemble, dropout, label smoothing, transfer learning 등과 같은 휴리스틱한 몇 가지 방법을 소개한다.
9.1. Explicit Regularization
아래와 같이 loss를 최소화하는 파라미터, 를 찾는다고 하자.
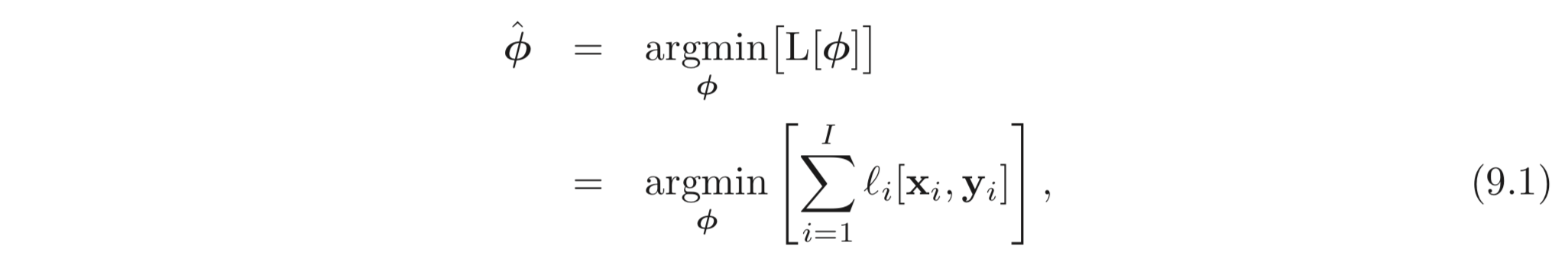
위와 같은 mimization term 을 특정한 parameter 로 유도하기 위해서는 아래와 같이 추가적인 term 을 loss에 추가해야한다.
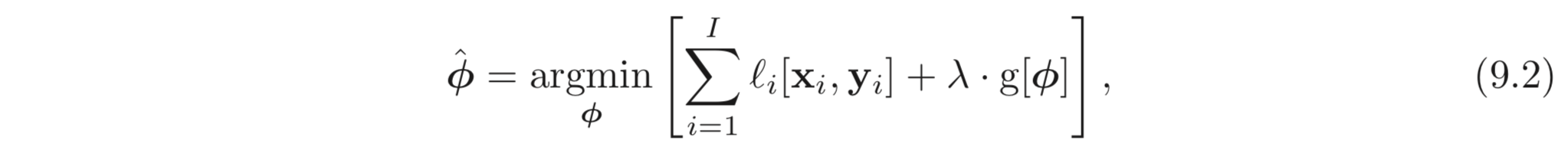
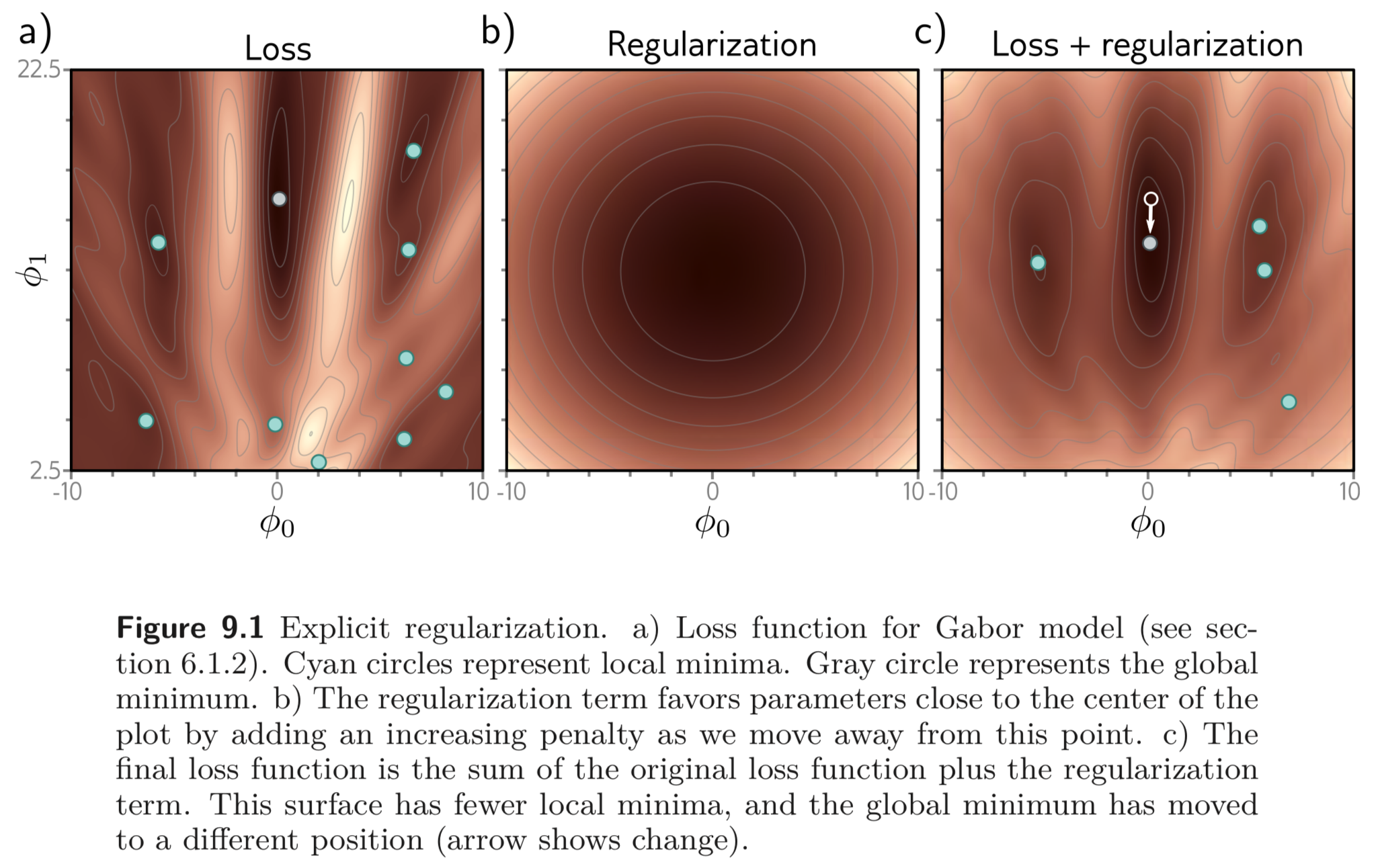
여기서 는 parameters 가 원하지 않는 방향으로 학습될 때 큰 값을 갖는 scalar 를 return 한다. 는 양수이며 training loss와 regularization term 의 상대적인 contribution 을 제어한다. regularization term 이 추가된 loss 함수는 일반적으로 기존의 loss 함수와는 다른 minima 를 갖는다. 따라서 학습의 결과로 다른 parameters 값을 갖도록 수렴한다. 아래 Fig. 9.1 c) 는 이를 보인다.
9.1.1. Probabilistic Interpretation
Regularization 은 probabilistic 한 관점에서 볼 수 있다. 아래 식은 maximum likelihood criterion 으로부터 얻은 loss 함수이다.
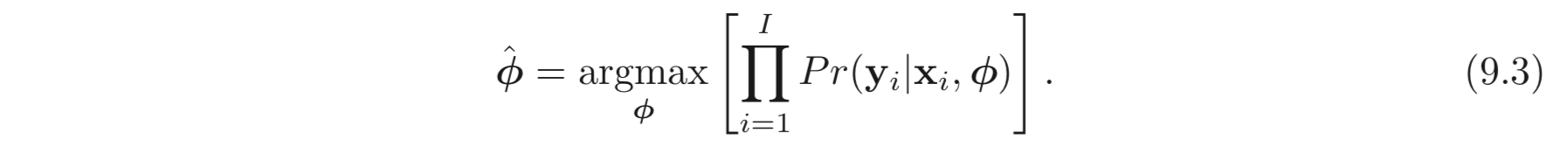
Regularization term 은 아래와 같이 data를 보기 전의 파라미터에 대한 knwoledge인 prior, 로 여길 수 있다.
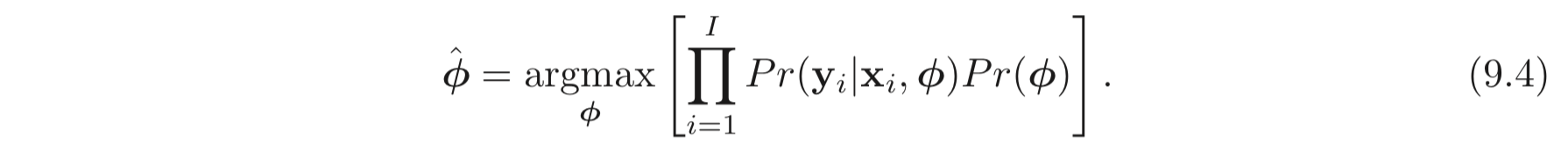
Negative log-likelihood loss function 으로 생각을 한다면, 9.4. 식에 log 를 씌우고 을 곱하면 regularization term, 와 같다.
9.1.2. L2 Regularization
앞선 논의에서는 regularization term 이 “어떤” 솔루션을 penalize 해야하는지에 대한 질문을 살짝 피해갔다. 뉴럴넷은 굉장히 다양한 어플리케이션에 적용될 수 있기 때문에 일반적인 표현을 사용하였다. 가장 널리 사용되는 regularization term 은 parameteres의 값들의 제곱의 합 () 을 penalize 하는 L2 norm 이다.

이는 또한 Tikhonov regularization, ridge regression 혹은 Frobenius norm regularization 으로도 알려져있다. 일반적으로 L2 regularization 은 뉴럴넷에서 bias 가 아니라 weights 에 적용된다 따라서 이를 weight decay term 으로도 부른다. weight 의 값이 작게끔 유도하며, 따라서 출력 함수가 더욱 smooth 해진다.
이를 관찰하기 위해 output 이 마지막 hidden layer 의 activations 의 weighted sum 이라고 하자. 만약에 weights 의 파라미터들이 작다면, output도 조금씩 변할 것이다.
아래 Fig. 9.2 는 weight decay 를 적용하고 서로 다른 를 사용하여 학습되는 결과를 플롯하였다.
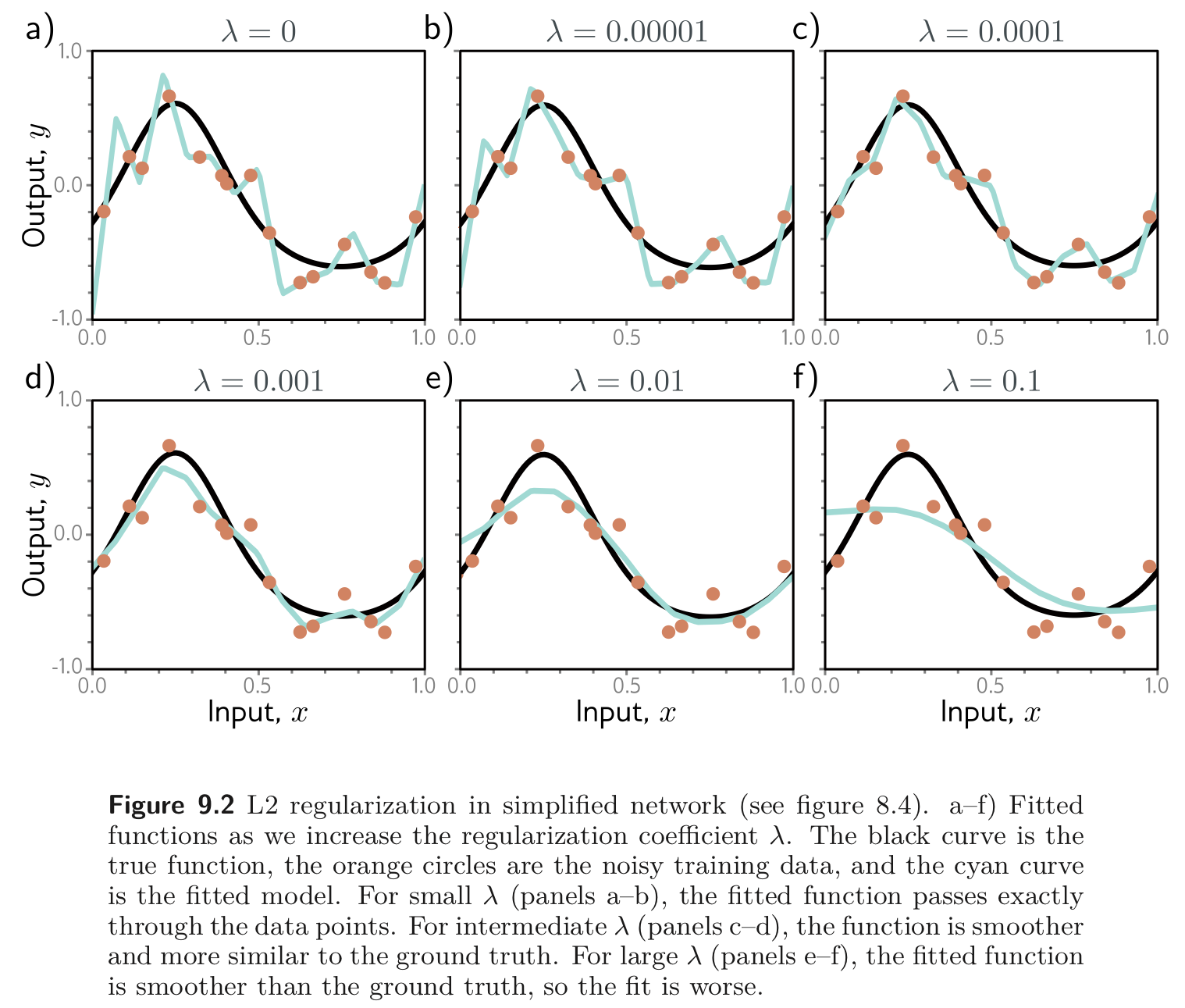
weight decay 가 커질 수록 더 smooth 한 함수가 만들어지지만 정확도는 떨어진다. 이는 아래와 같은 두 가지의 이유로 test performance 를 증가시킨다.
- regularization term 을 추가하는 것은 모델이 학습 데이터에 집착 (slavish adherence = 노예 같은 근성) 하는 성향과 smooth 함을 trade-off 하는 것이다.
- 모델이 over-parameterized 됐을 때, 추가된 모델의 capacity 는 학습 데이터가 없는 공간을 표현한다. 여기서 regularization term 은 서로 가까운 데이터 포인트들의 간의 보간을 smooth 하게 하는 함수들을 선호한다.
9.2. Implicit Regularization
최근 알려지게된 흥미로운 사실은 GD나 SGD 가 loss 함수의 minimum 으로 “중립적으로” 향하지 않는다는 것이다. 이말인즉슨, 각각이 다른 솔루션보다 선호하는 특정 솔루션을 선호하는 것을 보인다는 의미다. 이를 implicit regularization 이라고 한다.
9.2.1. Implicit Regularization in Gradient Descent
step size 가 극소인 continuous version 의 GD 를 고려해보자. 이는 아래 식과 같다.

GD는 이러한 과정을 만큼의 step size 만큼 반복하여 이 과정을 근사한다.:
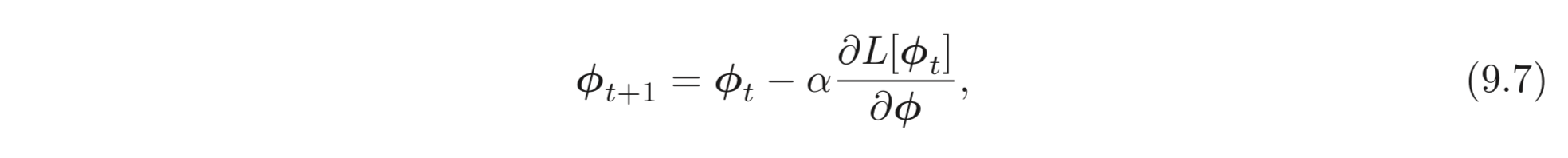
이러한 이산화 (discretization) 는 continuous path 로 편차 (deviation) 가 생기는 원인이 된다. 이러한 편차는 원본 loss, 위에서 이산화된 버전으로 같은 위치에 도착하도록 하는 continuous case 들을 위한 변형된 loss term, 을 유도해보면 알 수 있다. 이는 다음과 같이 나타낼 수 있다. (무슨 말인지 전혀 모르겠다..)
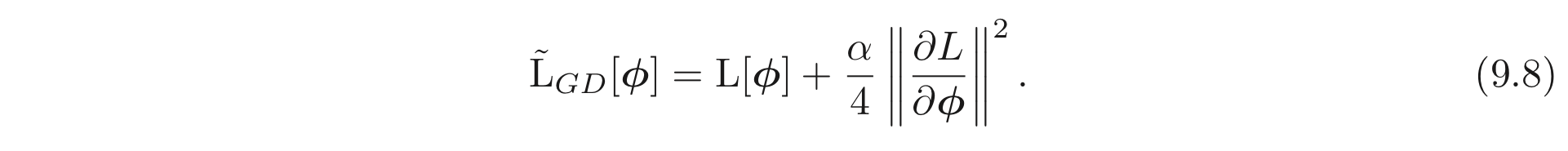
다시 말해, 위와 같이 이산화된 경로는 gradient norm 이 큰 위치에서 시작한다는 것이다. 이는 어찌됐든 gradients 가 0이 되는 minima의 위치를 바꾸지 않는다. 하지만, 이는 다른 곳에서 effective(?) loss function 을 바꾸고 다른 minimum으로 수렴할 수도 있는 optimization 경로도 바꾸게 된다.
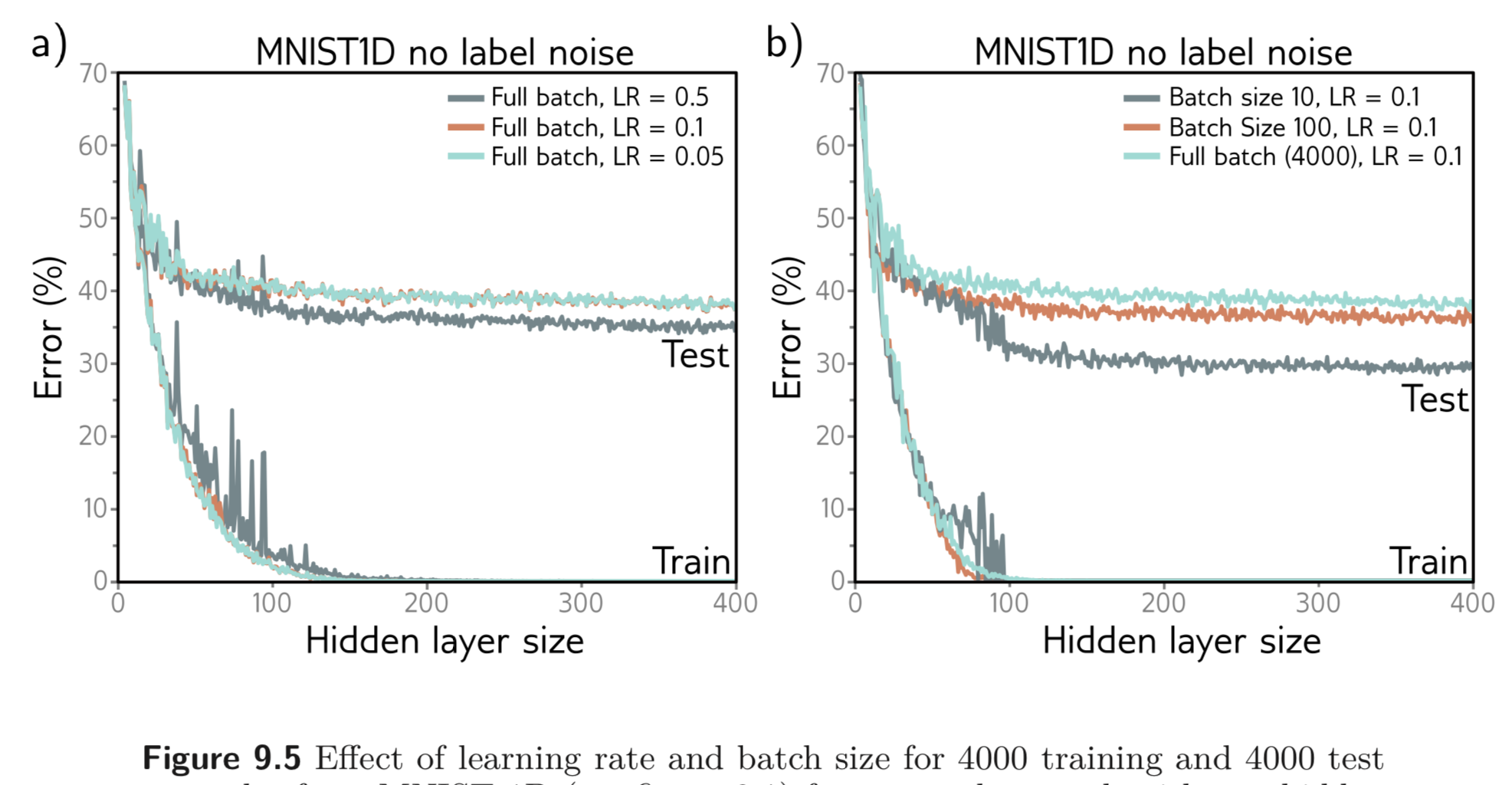
Gradien Descent 로 인한 implicit regularization 은 큰 step size를 갖는 full-batch GD 가 더 나은 일반화를 한다는 사실의 원인일 수 있다. (왜..?) Fig. 9.5 a) 를 보라.
9.2.2. Implicit Regularization in Stochastic Gradient Descent
위와 같은 맥락의 분석을 SGD에도 적용해볼 수 있다. 이제 continuous version이 가능한 SGD 의 평균이 도달하는 같은 곳에 가도록 하는 변형된 loss function 을 구해보자 (?) 이는 아래와 같이 구할 수 있다.
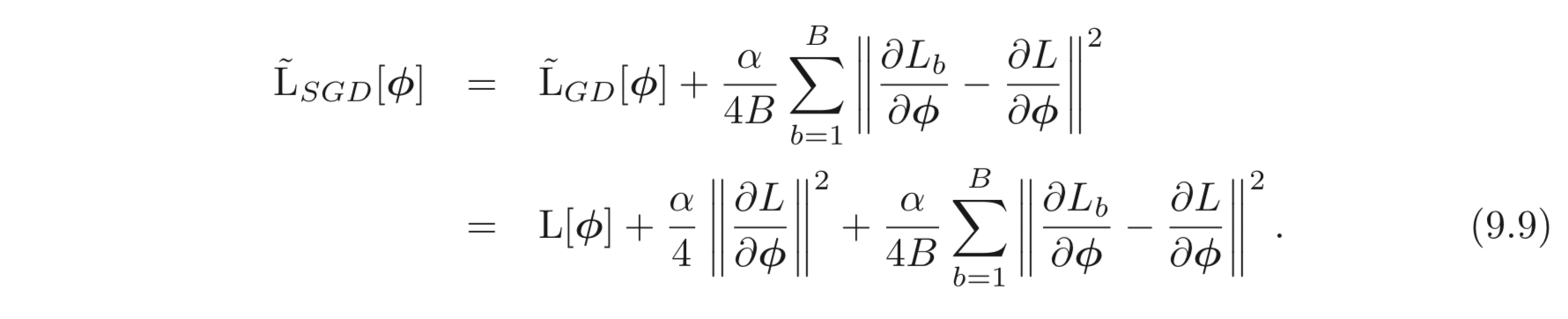
는 batch의 번째 loss 이며 는 각각 전체 데이터 , batch 의 각각의 loss 이다. 이는 아래와 같이 계산된다.
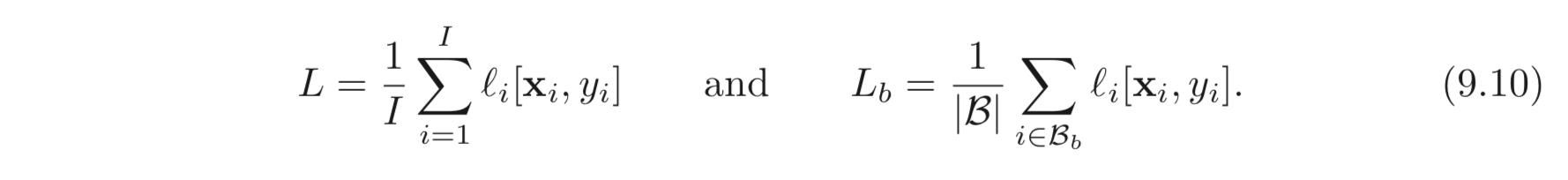
Eq. 9.9 는 batch losses 의 gradients의 variance에 대응되는 추가 regularization term이 있음을 보인다. 다시 말해, SGD는 암시적으로 gradients가 안정적인 위치를 선호한다는 것이다 (variance 가 작은 곳은 안정적이니까). 그리고 다시 한번 이는 optimization process의 경로를 수정하나 꼭 global minimum의 위치를 바꾸는 것은 아니다.
SGD는 GD보다 일반화를 더 잘한다. 그리고 batchsize가 작을 수록 큰 것보다 더 잘한다. [Fig. 9.5 b) 를 보라.] 이를 나타내는 하나의 설명은 내재된 랜덤성이 알고리즘으로 하여금 loss function 의 다른 부분에 도달하게 한다는 것이다. 이는 몇몇의 데이터를 완벽하게 설명하고 다른 데이터는 완전히 배재하기 (큰 batch variance) 보다는 모든 데이터를 잘 설명하는 솔루션 (작은 batch variance) 을 장려한다. 보통 후자가 더 나은 일반화 성능을 보인다.
9.3. Heuristics to Improve Performance
loss term에 명시적인 regularization term 을 더함으로써 학습 알고리즘이 좋은 솔루션을 찾도록 하는 것을 공부하였다. 이와 같은 현상은 SGD와 같은 알고리즘의 의도치 않은 부산물로써 암시적으로 발생하였다. 본 섹션에서는 일반화 성능을 향상 시킬 수 있는 다른 휴리스틱 방법들에 대해 알아본다.
9.3.1. Early Stopping
Early stopping 은 모델이 완전히 수렴하기 전에 학습 과정을 중단하는 것을 말한다. 이는 모델이 underlying function 를 얼추 잡아냈고 noise 에 overfitting 되지 않았다면 모델의 일반화 성능을 높인다. Fig. 9.6을 보자
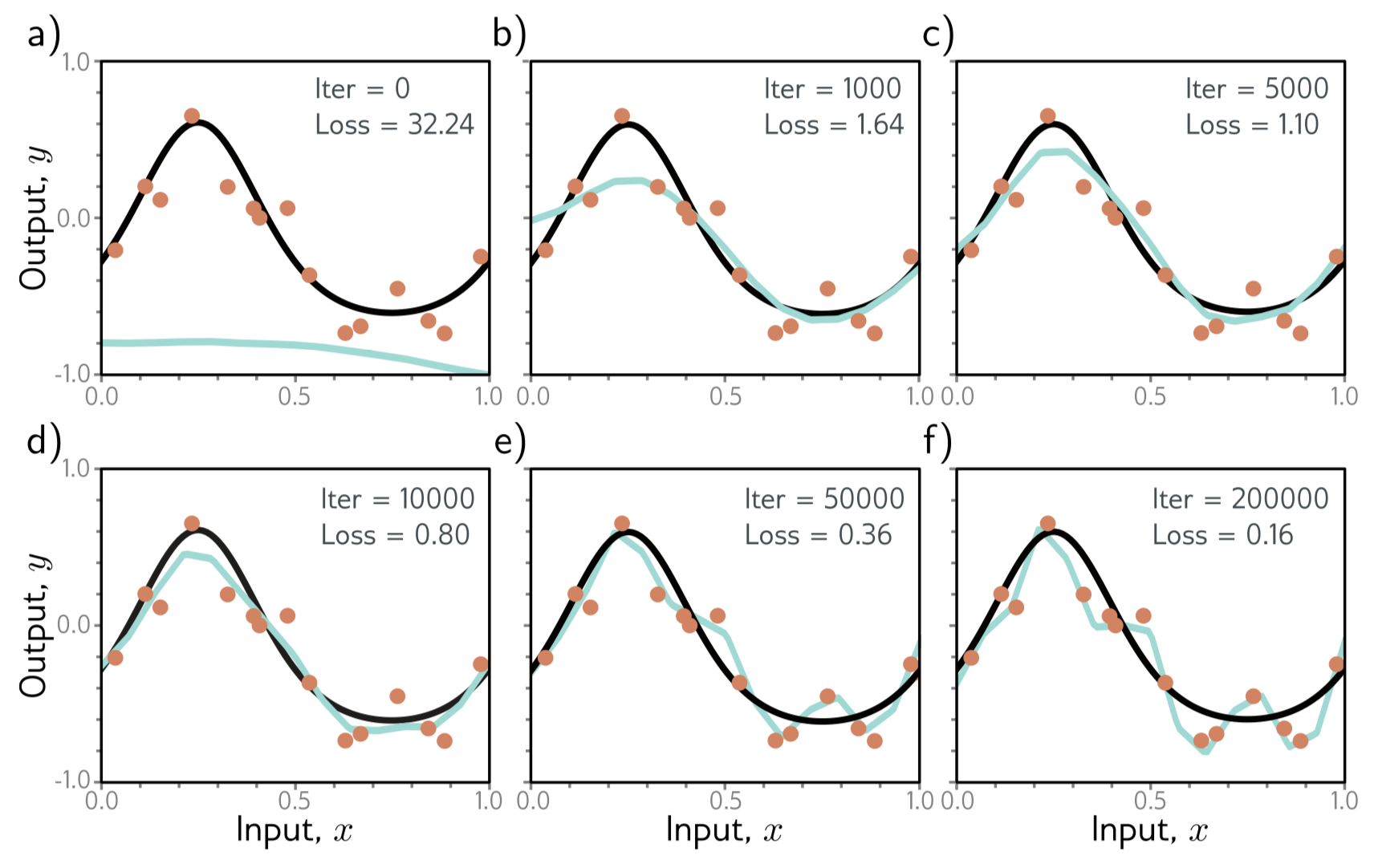
Fig. 9.6 f) 가 loss는 가장 낮지만 underlying function 과는 거리가 멀어보인다. 하지만 d) 는 loss는 가장 낮지 않지만 underlying function 을 가장 잘 나타낸다. Early stopping 을 생각하는 또 다른 방법은 모델의 weights가 초기에 작은 값으로 initialization 돼있이므로 단순히 너무 커지기 전에 학습을 중단하는 것이다. 따라서 L2 Regularization 과 비슷한 효과를 갖는다.
Early stopping 은 학습을 중단할 stpe 수, 딱 하나의 hyperparameter 를 갖는다. 이는 보통 validation set 을 이용하여 경험적으로 선택된다. 하지만 굳이 학습을 “중단”할 필요는 없다. 학습을 시작하고 매 번째 iterations 에서 validation set 의 성능을 평가하고 평가된 지표를 가지고 가장 좋은 성능을 갖는 모델을 “저장”하면 된다.
9.3.2. Ensembling
Generalization gap 을 줄이는 다른 접근법으로는 여러 개의 모델을 학습시키고 이들의 결과를 평균 때리는 것이다. 위와 같은 모델들을 ensemble 이라고 한다. 이는 test 성능을 안정적으로 향상 시킨다.
ensemble 을 하는 방법으로는 output 자체의 평균 (e.g. regression task) 을 구하던가 preactivations 들을 평균내어 softmax 에 먹이는 방법도 있다.
ensemble 은 각각의 output의 error가 각각 독립적이어서 이들의 평균을 계산하면 더해져 없어진다는 개념이다. 혹은 평균이 아니라 median 을 사용할 수 있으며 가장 많이 선택된 결과를 고를 수도 있다. (e.g. classification)
다른 모델을 사용하는 한 가지 방법은 서로 다르게 initialize 하여 학습하는 것이다. 이렇게 학습된 모델들은 상대적으로 덜 제한되었고 이들의 예측값이 서로 다를 수 있다. 따라서 이러한 모델들의 출력의 평균을 사용하는 것은 하나의 모델을 사용하는 것보다 좋은 일반화 성능을 보일 수 있다.
두번째 방법은 학습 데이터에서 중복을 허용하여 샘플링하여 서로 조금씩 다른 여러 데이터셋을 생성하고 각각의 모델을 생성된 여러 데이터셋에 각각 학습 시키는 것이다. 이는 bootstrapping aggregating 혹은 짧게, bagging 이라고 알려져있다. (Fig. 9.7.)

9.3.3. Dropout
Dropout 은 SGD의 매 iteration 마다 hidden units의 결과 일부를 (주로 50%) 0 으로 빼버리는 것을 말한다. Dropout 은 모델이 특정 hidden unit에 의존하지 않도록 하며 어떤 hidden units 이 있던 없던 loss의 큰 차이가 생기지 않도록 전체적으로 작은 weight 값을 갖도록 한다. (Fig. 9.8)
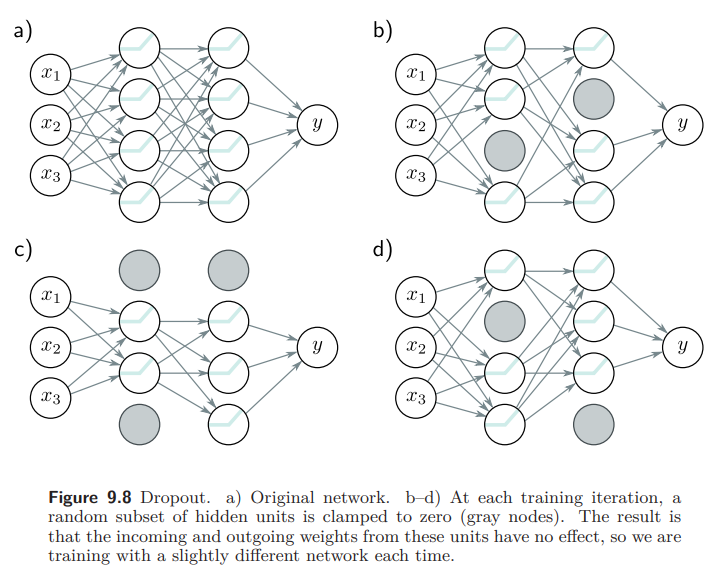
Dropout은 학습 데이터에서 멀고 loss에 영향을 주지 않는 test performance에 악영향을 끼치는 “꼬임” (kinks)을 함수에서 제거한다. 예를 들어 커브를 따라 움직일 때 연속으로 active 되는 3개의 hidden units 을 생각해보자. 첫 번째 hidden unit 은 큰 기울기를 갖도록 active 될 것이다. 두 번째 hidden unit은 약간 감소된 기울기를 가질 것이고, 세 번째 hidden unit 은 1, 2 번째 기울기를 감소하는 방향으로 바꾸기 위해 아주 작은 값을 가지게 될 것이다. (Fig. 9.9)

이러한 3번째 hidden unit 결과는 그 근처에서 좋지 않은 변화를 만들어낸다. 이는 loss를 변화 시키지는 않지만 generalization gap을 줄이지는 못한다.
이러한 방식으로 학습된 모델이 있다고 했을 때, 이 중에 하나의 hidden unit을 제거한다면 이는 큰 변화를 만들어낸다. activation의 절반씩을 랜덤하게 뽑아 학습을 시킨다면 각각의 hidden unit들이 이렇게 큰 영향을 주지 않도록 학습한다. 따라서 dropout 은 전반적으로 학습 데이터 “간”의 원치 않는 변화들을 점진적으로 줄임과 동시에 loss에도 영향을 주지 않는다.
test time 에서 모든 hidden units 을 active 하고 inference 할 수 있다. 하지만 학습중에 계속 activations의 절반만을 사용했기 때문에 모델은 학습 중에 모든 activations을 받아본적이 없다. 따라서 이를 맞춰주기 위해 weight에 를 곱해준다. 이를 weight scaling inference rule 이라고 한다. 또 다른 inference 방법으로는 Monte Carlo dropout 을 사용하는 방법이 있다. 학습할 때처럼 hidden units의 일부만을 사용하여 여러번 inference 하고 이들을 나중에 combine 하는 방식이다. 이 방식은 여러 random version의 모델의 결과를 사용하는 ensemble 과도 밀접하게 연관이 있어 보인다.
9.3.4. Applying Noise
Dropout은 activations에 multicative Bernoulli noise 를 적용한 것으로 해석할 수 있다. 이러한 아이디어에서 모델의 결과가 더욱 robust 해지도록 학습 중간에 모델에 noise를 적용하는 것으로 이어졌다.

하나의 방법으로는 입력 데이터에 noise를 더하는 것이다. (fig. 9.10.) 이를 통해 학습된 모델을 스무스하게 할 수 있다. Regression 문제에서 이는 입력에 대한 출력의 derivatives 를 제한하는 regularizing term 을 더하는 것으로도 볼 수 있다. 이의 극단적인 변형으로는 학습 알고리즘이 모델의 출력 결과에 큰 영향을 미치는 입력의 작은 변화를 찾도록 하는 adversarial training이 있다. 이는 noise 의 가장 안좋은 case를 찾는 것으로 볼 수 있다.
두번째 방법으로는 weights에 noise를 더하는 것이다. 이는 모델의 약간의 변화가 있더라도 여전히 그럴듯한 결과를 내도록 유도한다.
마지막으로 label에 noise를 더하는 방법이 있다. multiclass classification 에서의 maximum Likelihood criterion은 정확한 class를 정말 완벽하게 맞추는 것에 초점이 맞추어져있다. (e,g, one-hot encoding) softmax 함수는 정답인 logit이 무한대에 가깝게 크게 증가시키려고 하고, 정답이 아닌 logits에 -무한대에 가깝게 감소시키려고 한다.
이런 “과신”하는 행동을 제한하기 위해 만큼의 확률만큼은 부정확하다고 가정하고 이들을 정답이 아닌 다른 class들에게 나누어준다. 확률만큼 다른 class를 label에 부여할 수도 있지만 더 쉬운 방법이 있다. 바로 CrossEntropy loss에서 정답 label에는 을, 나머지 class에는 확률을 동일하게 나누어주는 방법이 있다. () 이러한 방법을 label smoothing 이라고 하며 generalization 성능을 향상시킨다.
9.3.5. Bayesian Inference
생략 (딥러닝에서는 사용 X)
9.3.6. Transfer Learning and Multi-task Learning
학습 데이터가 제한될 때, 다른 데이터셋을 사용하는 것으로 성능을 향상시킬 수 있다. Transfer Learning 에서 모델은 상대적으로 데이터가 풍부한 다른 task에 대하여 먼저 pre-trained 된다. 그리고 이렇게 pretrained 된 모델을 원래 task에 대하여 학습한다. 보통 마지막 레이어를 제거하고 원래 풀고자 하는 task에 맞게 설계된 레이어를 끼워 맞춘다. 그리고 새로운 레이어를 끼워넣은 모델을 원래 task에 대하여 학습한다. 이를 fine-tuning 이라고 한다. 모델이 다른 task 의 데이터로부터 좋은 내부 representation 을 학습하였고, 이는 original task에 사용될 수 있다.

Uploaded by N2T