Preface
이전의 챕터들에서 뉴럴넷, loss 함수 그리고 학습 알고리즘 등을 공부하였다. 이번 챕터에서는 학습된 모델의 성능을 평가하는 방법에 대해 공부한다. 충분한 capacity 를 갖는 모델은 학습 데이터셋에 대하여 완벽하게 fit 될 수 있다. 하지만 이러한 사실이 꼭 테스트 셋에 대하여 잘 generalize 했다고 보기 어렵다.
test errors의 세 가지 서로 다른 이유와 다음 세 가지 항목에 대한 이들의 상대적인 영향 (relative contributions) 도 살펴본다. [(1) task의 inherent uncertainty, (2) 학습 데이터의 양, (3) 모델의 선택]
8.1. Training a Simple Model

Fig. 8.1에서 제시한 것과 같은 MNIST-1D 데이터셋을 가지고 모델의 성능을 측정해본다. 이들은 0−9 의 digits에 대응되는 y={0,...,9} 로 구성된다. a) 는 각 digit의 예시 templates 이다. b) 는 해당 template을 랜덤하게 transform 한 것이며 c) 는 noise를 더했다. d) 는 이를 적절한 offset으로 총 40개로 잘라낸 것이다.
따라서 입력 dimension, Di=40, 출력 dimension, Do=10, hidden width =100 을 갖는 모델을 설계하고 출력값을 softmax 함수에 주어 최종적으로 확률값을 나타내도록 하였다. 이를 batch size = 100, LR은 0.1 을 총 150 epochs 만큼 학습시켰다. 그러면 약 4000 steps 쯤에 학습 데이터를 완벽하게 분류하며 loss는 거의 0에 수렴한다.
하지만 학습 데이터를 완벽하게 예측한다고 좋은 모델은 아니다. 모델은 학습 데이터를 아예 통째로 외워버릴 수 있으며 이럴 경우 새로운 데이터에 대해서 좋은 결과를 얻지 못한다.
따라서 모델의 “진짜” 성능을 측정하기 위해서 테스트 셋을 따로 분리해야한다. 이를 위해 약 1000개의 test sample을 생성하였다.

Fig. 8.2 는 test set에 대한 학습 에러 및 loss를 나타낸 것이다. 학습 error 는 점점 감소하기는 하지만 40% 언저리에서 내려가지 못하고 있으며 train set 에 비하면 한참이나 크다. train set 에 대해서는 완벽하게 학습했지만 test set에 대해서는 잘 예측하지 못하므로 모델은 잘 generalized 되지 못하였다.
loss는 반면 어느 순간까지는 감소하다가 증가하게 된다. 하지만 학습 error 는 거의 그대로 유지된다. 이는 모델이 학습을 거듭할 수록 더 높은 confidence로 틀리기 때문에 발생하는 현상이다. 이는 확률을 1로 맞추기 위해 pre-activation 이 무한대로 커져야하는 softmax 함수의 부작용 때문에 발생한다.
8.2. Sources of Error
본 섹션에서는 모델이 generalize 에 실패했을 때 생기는 error 의 원인을 살펴본다. 직관을 높이기 위해 아주 간단한 예시를 든다.

Fig. 8.3 은 quasi-sinusoidal function 을 보인다. 여기서 training set과 test set 을 [0,1] 에서 sampling 하며 고정된 variance 를 갖는 Gaussian noise를 더한다.

이를 위해 Fig. 8.4 와 같은 아주 간단한 shallow neural network 를 학습시킨다. 여기서 문제를 더 쉽게 보기 위해 각 weights, biases 는 각 “joints” 들이 균등하게 고루 분포되도록 선택된다.
만약 3개의 joints 가 있다면 0,13,23 이 되도록 한다. 그리고 적절한 optimization 을 통해 loss가 globabl minimum 에 도달하였다고 가정한다.
8.2.1. Noise, Bias and Variance
test error 의 원인으로는 크게 noise, bias, variance 가 있을 수 있다.

Noise Fig. 8.5 의 a) 를 보라. noise는 본 예제에서는 데이터를 생성하는 과정에 일부러 넣었다. 이는 정말로 확률적으로 존재하는 요소인데 이는 data가 잘못 레이블링 되있거나 아직 관측되지 못한 데이터가 있어 생길 수 있다. 물론 noise 가 없을 수도 있다 (완벽한 레이블링 혹은 deterministic 한 test set). 하지만 보통의 경우 noise 는 피할 수 없다 (insurmountable).
Bias 두 번째 원인은 모델이 데이터를 완벽하게 학습할만큼 유연하지 못하기 때문이다. 예를 들어 Fig. 8.5 의 b) 는 3개의 joints 를 갖는 모델은 optimal한 결과임에도 불구하고 quasi-sinusoidal function을 제대로 표현하지 못한다. 이를 bias 라고 한다.
Variance training set을 가지고 있다. 또한 이러한 데이터는 noise 와 구분이 불가능하다. 모델을 학습할 때 진짜 데이터셋을 관통하는 진리를 학습하는 것이 아니다. 그저 training set에 대한 loss를 줄이는 방향으로 학습될 뿐이다. 따라서 조금씩 다른 dataset에 대해서 서로 다른 결과로 모델이 학습된다. 이러한 것을 variance 라고 한다. SGD를 사용해도 variance가 존재한다.
8.2.2. Mathmatical Formulation of Test Error

8.3. Reducing Error
noise는 모델링이 문제를 해결할 수 없다. 하지만 bias, variance는 해결해 볼만하다.
8.3.1. Reducing Variance
variance 는 noisy한 training data로 인해 발생하였다. 이러한 문제를 해결하기 위해서는 training data의 양을 늘리면된다. 그러면 noise 들은 어림잡아 없어지고 입력 space도 잘 sampling된 것을 확실히 할 수 있다.
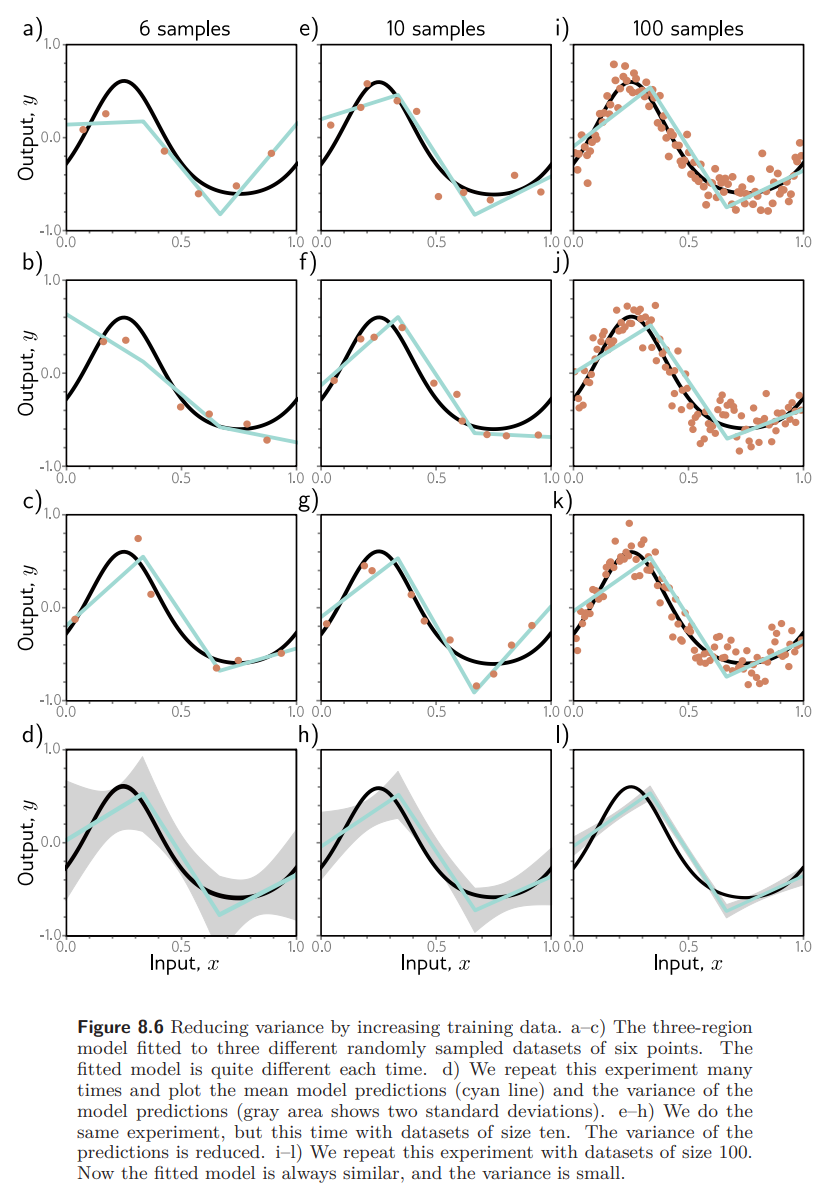
Fig. 8.6 은 training data 의 갯수가 6, 10, 100 개 일 때의 학습 결과를 보여준다. sample 의 갯수가 증가할 수록 학습된 결과가 거의 비슷해져 variance가 감소한다. 보통, 학습 데이터의 수를 늘리는 것은 거의 test 성능을 향상 시킨다.
8.3.2. Reducing Bias
bias 는 true underlying function 을 나타내지 못하는 모델의 무능해서 비롯한다. 이는 모델을 더욱 flexiable 하게 만들어 bias 로 비롯한 error 를 감소시킬 수 있음을 시사한다. 보통 model 의 capacity 를 증가시킨다.

Fig. 8.7은 regions 를 늘릴 수록 원래 함수였던 quasi-sinusoidal function 에 가까워진다는 사실을 보인다.
8.3.3. Bias-Variance Trade-off
하지만 Fig. 8.7 의 d-f) 는 capacity가 커질 수록 variance 가 증가함을 보인다. 결과적으로 모델의 capacity 를 증가시키는 것이 항상 test error 를 감소시키지는 않는다. 이를 bias-variance trade-off 라고 한다.

Fig. 8.8 은 capacity 가 증가함에 따라 variance 가 증가하는 것을 보인다. a-c) 는 데이터셋이 조금씩 달라져도 bias 때문에 a, b, c) 모두 학습된 결과가 비슷하다 (low variance). 하지만 d-f) 는 모델이 더욱 유연하기 때문에 데이터셋이 조금씩 다를 때마다 그 결과가 크게 바뀐다 (high variance).
capacity 가 높아 모델이 유연한 것은 training set 에 모델이 확실히 fitting 될 수 있는 여지가 있음과 동시에 이는 disadvantage 이다. 왜냐하면 이러한 유연함이 noise 까지도 모델링 해버리기 때문이다. 이러한 현상을 overfitting 이라고 한다.
앞선 관찰을 통해 너무 크지도, 작지도 않은 적다한 크기의 capacity 가 있음을 가정해볼 수 있다.
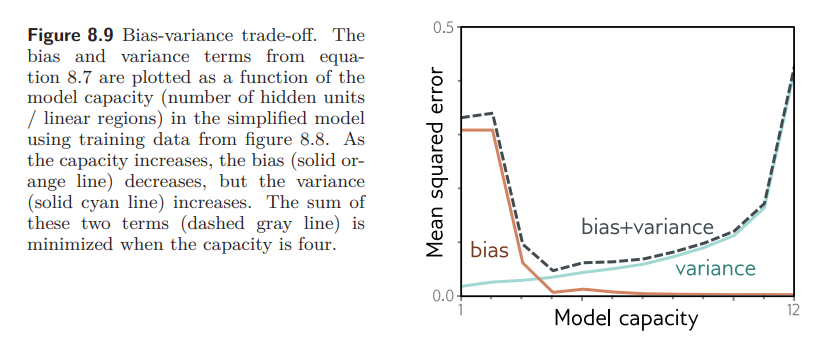
Fig. 8.9. 는 Bias-variance trade-off 를 보여준다. 3의 capacity를 가질 때 가장 test error가 작은걸 볼 수 있다.
8.4. Double Descent
앞서 bias-variance trade-off 를 보았다. 이제는 다시 MNIST-1D dataset 으로 돌아가 실제로는 어떻게 학습되는지 살펴본다. 10,000장의 training data, 5,000장의 test data 를 사용했으며 capacity가 증가함에 따라 test performance 가 어떻게 변하는지 관찰한다. Adam을 사용하였고, lr=5×10−3 을 사용했으며 full batch 로 4,000 step씩 학습 하였다. (4,000 epochs)

위 Fig. 8.10 은 2개의 hidden layers 를 가진 뉴럴넷의 hidden layer의 width 를 증가시킴에 따른 train, test error 플롯을 보인다. Training error 는 capacity 가 증가함에 따라 급격히 감소하며 금방 0에 가까워진다.
(
−−− 의 수직선은 training example 의 수와 parameter의 수가 같아지는 지점을 의미한다.)
Test error 는 모델의 capacity를 증가 시킴에 따라 감소한다. 하지만 bias-variance trade-off 에서 기대했던 것과는 달리 다시 증가하지 않고 계속 감소한다.
Fig. 8.10 b) 에 본 실험을 training label에 noise를 추가하여 다시 반복하였다. (잘못된 labeling e.g. 9를 2로 labeling.) 역시 다시 training error 는 0으로 감소한다. 하지만 이번엔 모델이 학습 데이터를 memorize 하기 까지 조금더 시간이 오래 걸렸다. test erorr는 모델이 데이터를 정확히 학습하는 지점까지 (== memorize 하는 지점)는 전형적인 bias-variance trade-off curve를 보인다.
그러나 그 이후부터는 우리가 기대했던 바와는 다르게 test error 가 다시 감소하는 현상이 발생한다. 모델에 capacity를 충분히 더한다면 앞선 bias-variance trade-off 의 curve의 최소값보다 더 작은 값까지 error가 감소할 것이다.
이러한 현상을 double descent 라고 한다. Fig. 8.10 d) 를 보면 noise를 더할 수록 이러한 현상이 더욱 도드라진다. double descent 현상이 생기는 지점을 critical regime 이라고 한다. 커브가 생기는 지점까지를 classical regime or under-parameterized regime 이라고 하며, 그 이후를 modern regime, over-parameterized regime 이라고 한다.
8.4.1. Explanation
double descent 현상은 예상치 못했으며 최근에 알려지게 되었다. 이는 다른 두 가지의 현상이 상호작용하며 발생한 것으로 알려져있다. 하나는, test performance 가 모델이 딱 데이터를 외워버릴 정도의 capacity를 가질 때 잠깐 나빠지는 현상과, 둘 째로 training performance가 완벽해진 이후에도 capacity가 증가함에 따라 test performance 가 좋아지는 것이다.
첫 번째 현상은 앞서 bias-variance trade-off 현상에서 기대한 바와 정확히 일치한다. 하지만 두 번째 현상은 아직까지 왜 그런지 구체적으로 알려진바가 없다. 이러한 현상을 이해하기 위해서 모델이 loss를 0에 가깝게 학습 시킬 수 있는 capacity를 가진 순간에는 학습 데이터에 거의 완벽하게 학습을 한 것이다. 이는 따라서 모델에 capacity를 추가하여도 성능 향상을 기대할 수 없음을 알 수 있다. 생겨도 training data points 사이 에서 생기게 된다.
data points 에 대하여 extrapolates 할 때 모델이 다른 솔루션보다 하나의 솔루션을 우선하는 것을 inductive bias 라고한다. (e.g. CNN (pixel 간의 정보는 서로 관련이 클 것이다.), RNN (이전 step의 정보는 다음 step의 결과와 밀접하게 연관이 있다.))
데이터 간의 모델이 취할 행동은 중요하다. 왜냐하면 high-dimensional space 에서는 학습 데이터들이 굉장히sparse 하게 존재하기 때문이다. 학습 데이터의 수를 high-dimensional 한 학습 공간이 이를 압도하는 경향을 curse of dimensinonality 라고 한다.
이 때문에 high-dimensional 한 space 에서의 문제는 Fig. 8.11 a) 와 같이 보일 것이다.

Double Descent 의 원인으로 추정되는 설명은 우리가 모델에 capacity 를 더할 수록 모델은 가까운 data points 간을 더 smooth 하게 interpolate 한다는 것이다. 학습 데이터간에 무슨 일이 벌어지는지 모르는 현재 상황으로써는 이러한 smooth 함을 가정하는 것이 새로운 데이터를 일반화하는 것에 꽤나 그럴싸한 설명이 된다.
Fig. 8.11 은 모델에 capacity를 증가시킴에 따라 각 데이터 사이 를 더욱 smooth 하게 연결하는 것을 보인다. 파라미터의 수가 학습 데이터의 수와 비슷해지면 모델은 학습데이터를 있는 그대로 정확하게 표현하기 위해 왜곡된다. 이는 double descent 의 peak 가 왜 생기는지 명확하게 설명한다.
capacity가 증가하면 모델은 새로운 데이터에 대하여 더 잘 일반화 할 수 있는 smoother 한 함수를 구축할 수 있게 된다. 하지만 이러한 설명이 over-parameterized 된 모델이 smoother 한 함수를 만드는지에 대해서는 설명할 수 없다.

Fig. 8.12 는 50 개의 hidden units 을 가진 모델이 학습될 수 있는 3가지의 경우에 대해 보인다. 각 케이스에서 모델은 loss가 0이 되도록 데이터를 정확하게 학습한다. 만약 double descent 의 modern regime 이 학습된 모델이 smooth 한 함수를 학습하는 것으로 설명된다면 정확히 무엇이 이러한 smoothness 를 유도하는 것일까?
이러한 질문에 대한 답은 아직 모호하다. 하지만 2가지의 가능성이 있는데 하나는, network initialization 이 이러한 smoothness 를 유도할 수 있다는 점이고, 모델은 smooth 함수의 범주에서 벗어나는 함수를 학습하지 않는다는 점이다. 두 번째로는, 학습 알고리즘이 웬걸 smooth function 으로 수렴하는 것을 “선호” 한다는 점이다.
어떤 솔루션을 이와 동일한 솔루션들의 일부로 유도 (”biases”) 하는 어떠한 factor 를 regularizer 라고 부른다.
8.5. Choosing Hyperparameters
이전 섹션에서 우리는 모델의 capacity가 변함에 따라 test performance 가 어떻게 변하는지 살펴보았다. 하지만 classicla regime 에서는 bias (true underlying function (e.g. 무한에 가까운 데이터셋이 있다면 가지고 있을 함수)) 와 variance (학습 데이터는 샘플된 데이터이기 때문에 생기는 true underlying function 과의 차이) 를 알 수 없다.
modern regime 에서는 test performance 가 더이상 나아지지 않을 때까지 capacity 를 얼마나 추가해야할지 알 수 없다. 따라서 실전에서 모델을 어떻게 선택해야하는가? 라는 질문을 남긴다.
DNN에서 capacity 는 hidden layers 의 수와 이의 hidden units 갯수에 따라 결정된다. 더 나아가서 learning rate, batch size 등의 다른 요소들도 test performance 에 영향을 주는 팩터들이다. 이들을 묶어 hyperparameters 라고 한다.
Uploaded by N2T