본 포스팅은 Stanford Univ. 의 CS149 2022 fall 수업을 정리한 내용임을 밝힙니다.
Agenda
- software engineering 의 관점에서 컴퓨터 아키텍쳐를 살펴볼 예정
- Key points
- parallel execution (multi-core, SIMD)
- limitations of memory access
Previous Work

Fetch/Decode: 어떤 instruction을 다음에 수행할지 결정
ALU: 앞서 결정된 instruction을 “수행”하는 역할
Execution Context: 프로그램의 state(context, 프로세스가 수행 중인 그 순간의 registers에 저장된 값들을 의미함. 스택에 저장됨.) 를 유지함.
Superscalar processor
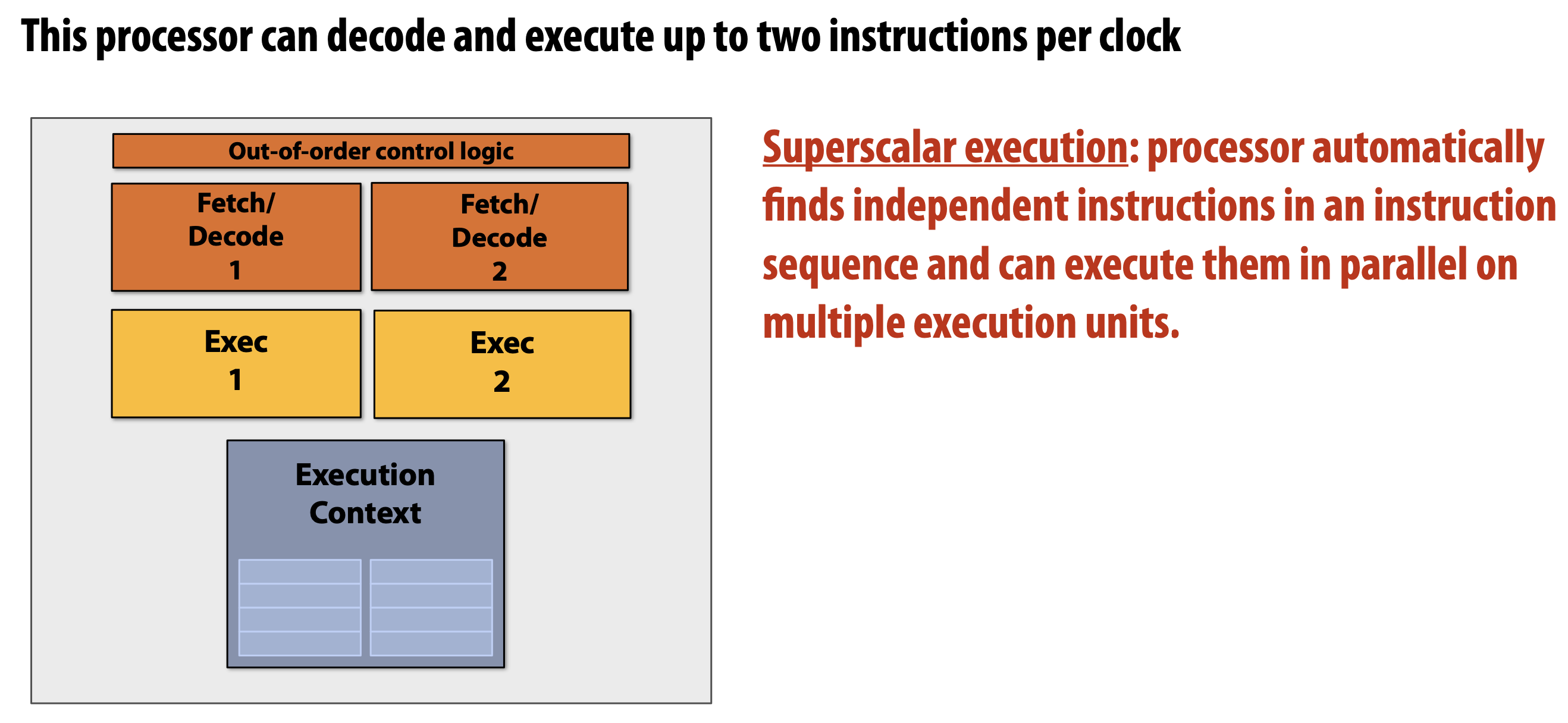
- 한 번에 여러 instructions 들을 수행할 수 있다. 하지만 동시에 수행 되는 instructions 는 서로 independent 해야한다.
- 이를
ILP를 활용하여 dependent 한지 아닌지 확인할 수 있지만, 이것만을 가지고는 scalable 한 성능향상을 얻기 어려움. 따라서 다른 방법이 필요함.
Parallelism
Pre Multi-core Era Processor
지금의 multi-core 이전에는 하나의 instruction stream 어떻게 하면 더 빠르게 수행할까를 고민한 경우가 많았음. 더 많은 트랜지스터를 더 큰 캐시, 더 큰 out-of-order logic module, branch predictor에 투자하였다.
Multi-core Era Processor
Multi-core parallelism
이런 경우 하나의 코어는 기존의 “fancy” 한 싱글 코어의 성능에는 75% 정도밖에 내기 못하지만 ×2 니까 결국 50%의 성능 향상을 얻음. (성능 향상의 가능성이 더 높음.)
하지만 우리의 프로그램들은 병렬적이지 않다. 따라서 이들을 병렬적으로 프로그래밍 해야한다. 크게 두 가지 정도를 생각해볼 수 있다.
- thread 사용. (c++표준인 std::thread를 사용하여 여러 개의 core를 사용하도록 명시적으로 프로그래밍.)
- Data-parallel expression 사용. (아래 예시 코드)

빨간 글씨로 forall 로 선언된 for loop은 프로그래머에 의해 “명시적으로” independent 하다. 라고 컴파일러에게 알려주는 것이다.
이렇게 작성한 경우, for loop이 돌면서 각각의 수행에서 입력이 되는 값만 다르고 모두 같은 instructions를 수행하는 것을 볼 수 있다.
single instruction multiple data
이렇게 Abstraction(즉, independent하게 잘 나누어 두는 것)을 잘 해두면 multi-core parallel과 SIMD를 사용하는 vectorized parallel 둘 다 auto generation하거나 사람이 explicit하게 리팩토링하기 좋다.
Data Parallelism (SIMD)
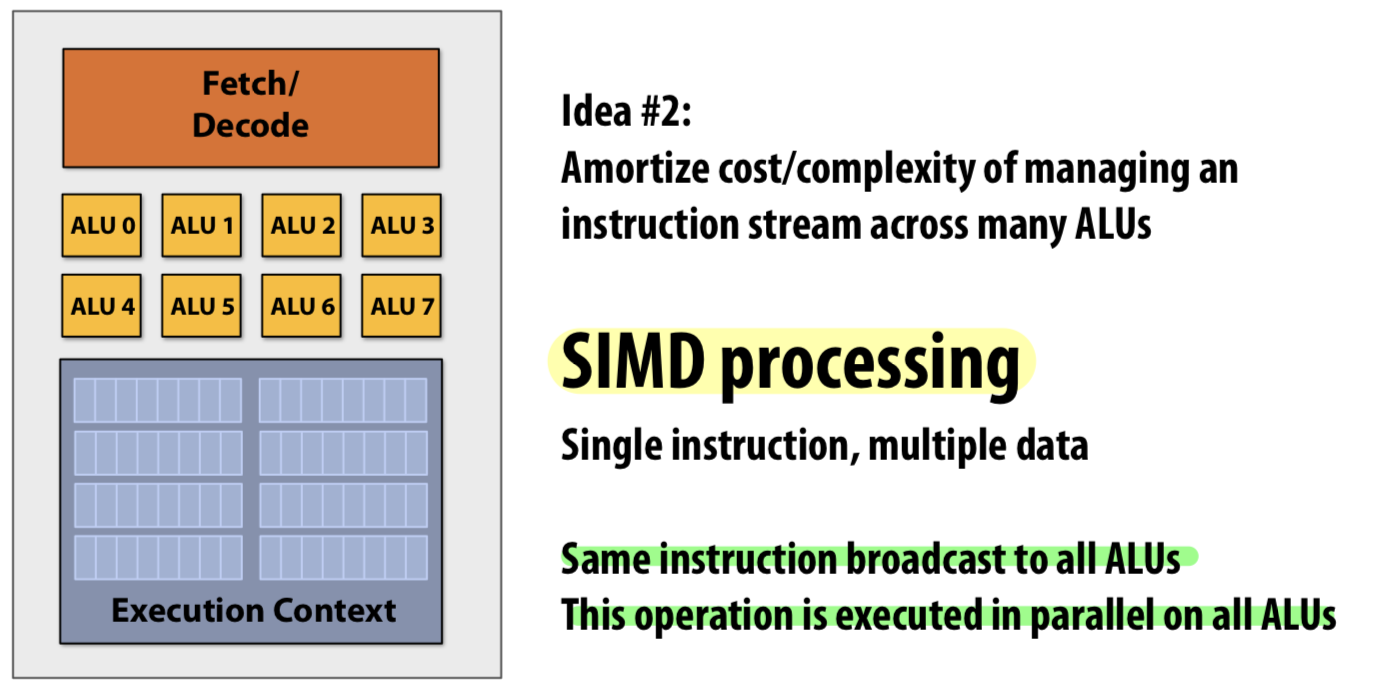
바로 SIMD processing 을 사용하는 것이다. 아래 예시가 있다.

SIMD를 적용한 vectorized version의 프로그램이다. intrinsic datatypes과 함수를 사용한다. 위 예제에서는 8개의 32bit 연산을 한 번에 수행한다.
vectorized code의 문제는 branch에 있다. 아무리 같은 코드를 수행하더라도 branch는 결국 따로 수행되어야하기 때문이다. 이러한 경우에는 Mask를 사용하여 특정 branch에서 작업을 수행할 data 들을 선별한다.
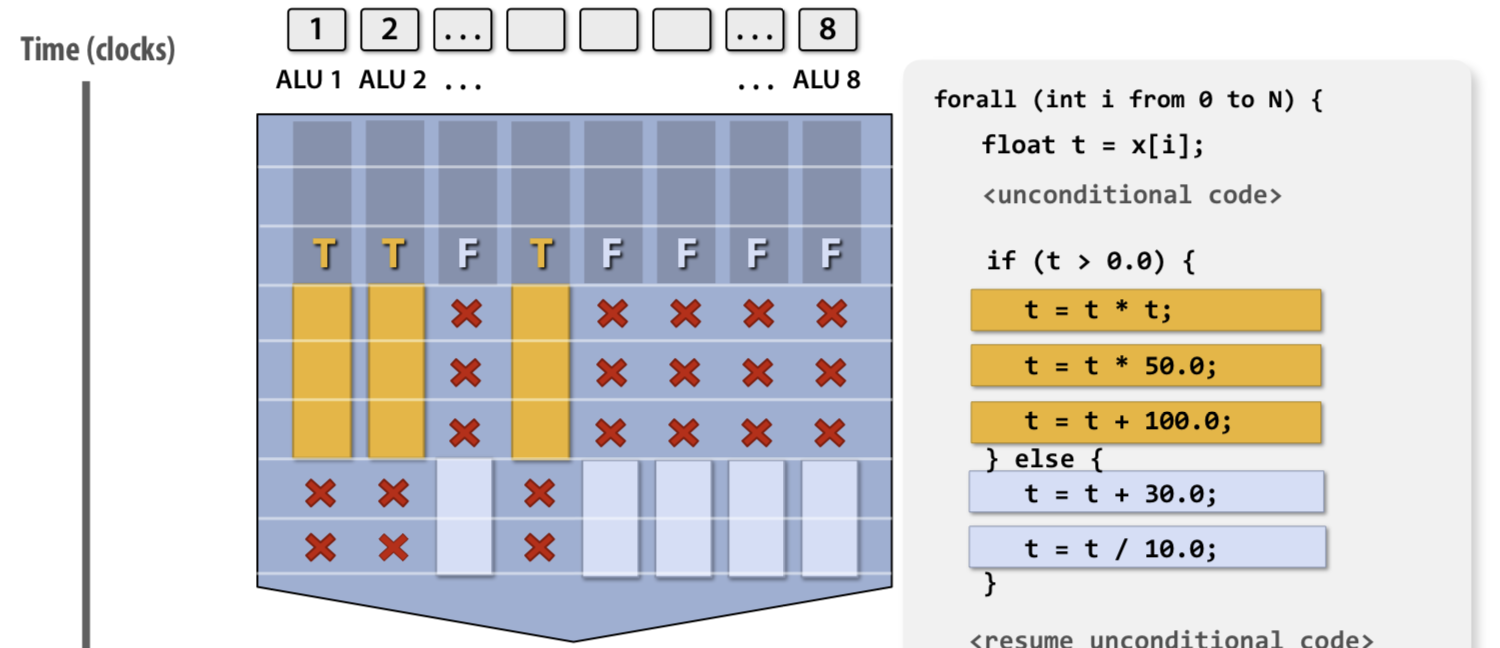
SIMD는 CPU 마다 지원하는 SIMD instruction set이 있기 때문에 이를 확인하여 사용하면된다.
SIMD를 활용하여 instructions을 생성하는 방법은 크게 3가지로 나뉜다.
- Manually: “intrinsics” datatype과 함수들을 사용하여 명시적으로 프로그래머가 SIMD instructions을 사용하게 하는 방법
- Half-manually: 앞선 예제의 forall 과 같이 선언하여 컴파일러에게 “이 부분은 병렬처리가 가능해” 라고 알려주어 컴파일러가 알아서 병렬화하도록 하는 방법
- Automatic: “auto-vectorizing”과 같은 컴파일러가 알아서 코드를 분석해서 vectorized 하도록 하는 방법
Summary: 3가지의 parallel execution methods
Superscalar: 하나의 instruction stram에서 결정된 ILP를 이용한다. 따라서 하나의 instructions stream에 있는 ILP가 같은 서로 다른 instructions을 parallel하게 수행함.Parallelism이 하드웨어에 의해 자동으로 수행됨. (프로그래머의 개입 X)
SIMD: “하나의 코어에서” 같은 instuction을 여러 개의 ALUs가 동시에 처리한다. data-parallel(같은 연산을 서로 다른 데이터에 대해서 여러번 수행할 때, e.g. 이미지 프로세싱) 에서 효율적이다.Vectorization이 compiler에 의해 될 수도 있고 (explicitSIMD) 하드웨어에 의해 런타임에 수행될 수도 있다 (implicitSIMD).
Multi-core: 여러 개의 코어를 동시에 사용.thread level 에서의 parallelism을 제공: 완전히 다른 instructions을 서로 다른 코어에서 따로 수행함. 프로그래머가 명시적으로 thread를 생성하여 이들을 parallelization 해야한다. (std::thread 등을 사용)
Memory Access
Memory access latency: 메모리 시스템에서 processor에게 데이터를 전달하는데 걸리는 총 시간.
Stall: 다음 instruction을 수행하기 위해 이전 instruction을 기다려야하는데 이전 instruction이 아직 안끝나서 다음 instruction을 수행하지 못하고 있는 상태.
Hiding Stall
“arithmetic instructions” (계산 연산)은 1-2 cycle 안에 수행이 끝나지만, “memory access”는 100 cycle씩도 걸리기 때문에 Memory access 는 stall의 주요 원인임.

이러한 문제를 해결하기 위해 modern CPU 들은 cache를 두어 이러한 stall 시간을 줄인다. 하지만 속도가 빠른 만큼 cache는 무진장 비싸기 때문에 이를 잔뜩 둘 수는 없다. 따라서 레벨을 두어 cache를 나누는데 아래는 레벨에 따른 캐시들과 램의 access latency이다.
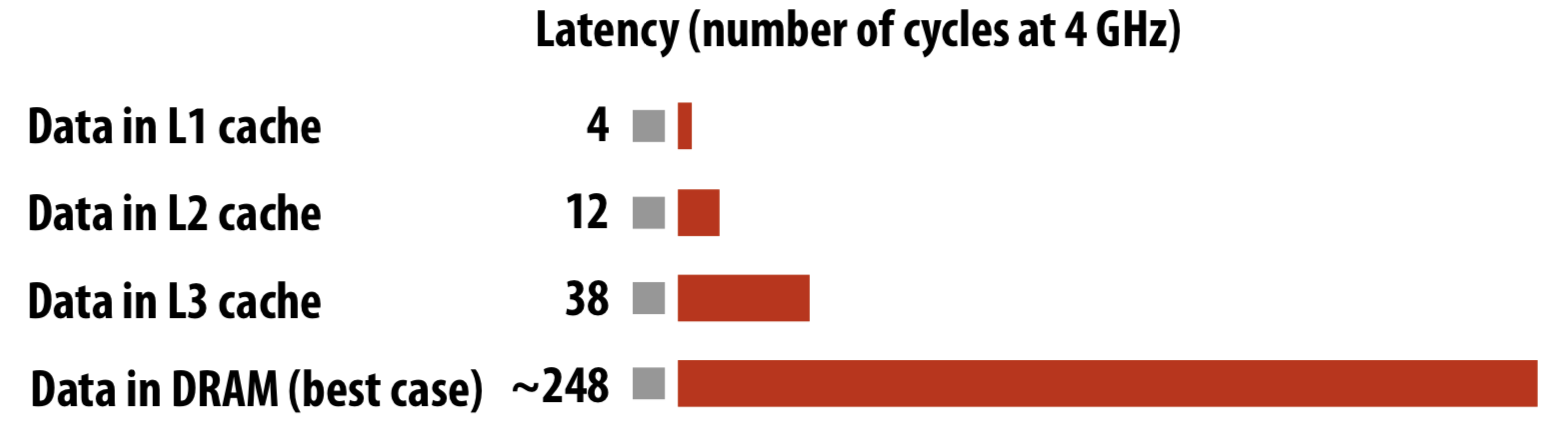
현대의 대부분의 CPU는 다음에 어떤 데이터가 사용될지를 예측하여 데이터를 캐시에 넣어 두는 prefetching 을 하는 logic이 구현돼있다.
cache hit, 그렇지 않으면 cache miss 라고한다.만약 stall 되었을 때 multi-threading 이 구현된 상황이라면 그냥 다른 thread를 수행하면 된다 (interleave). 이를 hiding stall 한다고 한다.
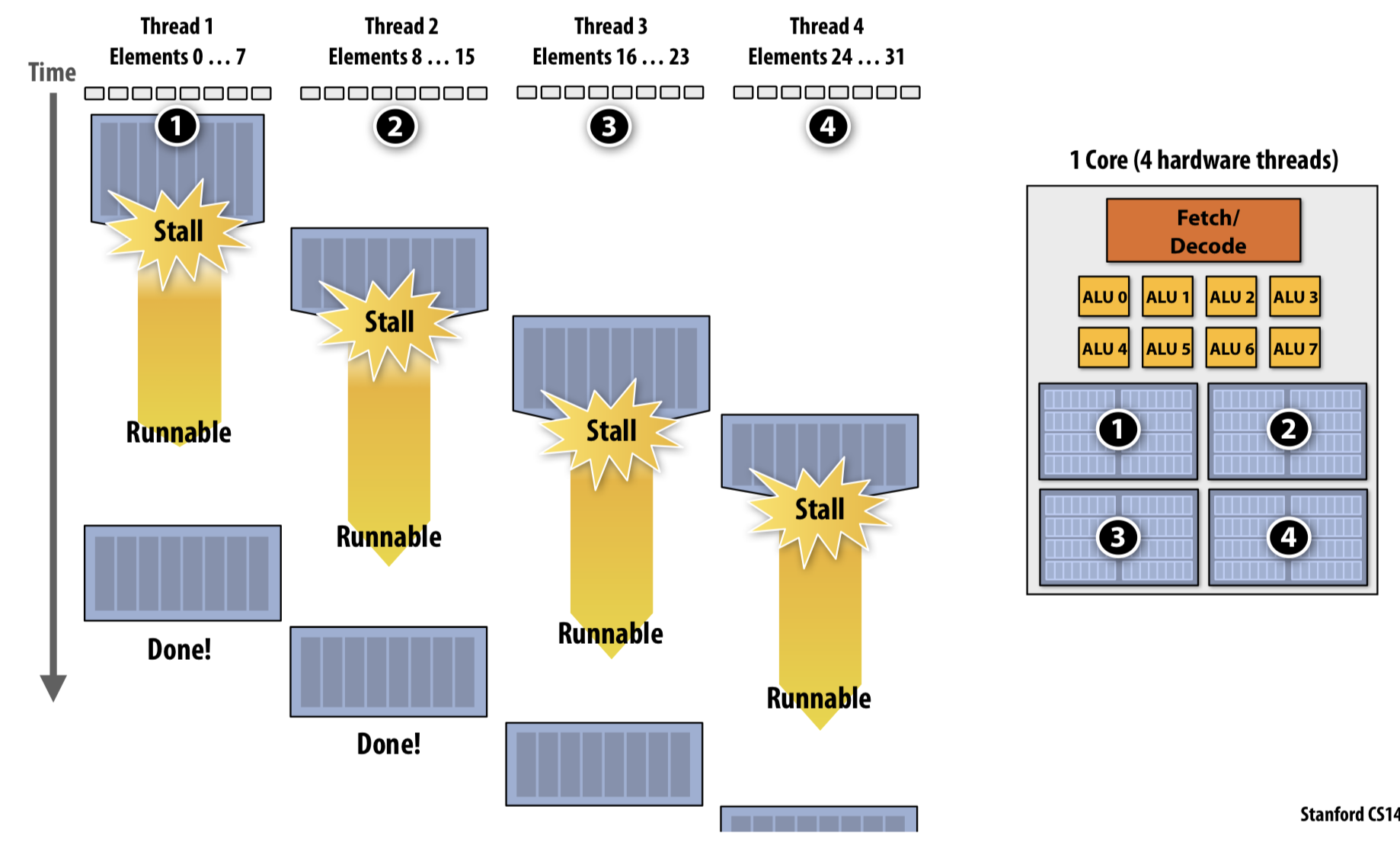
하지만 이렇게 hiding stall 은 공짜가 아니다. 이를 뒷받침하기 위해 여러 threads를 빠르게 switching 해야하는데 (context switching) 당연히 여기에 overhead가 있다.
Utilization of core
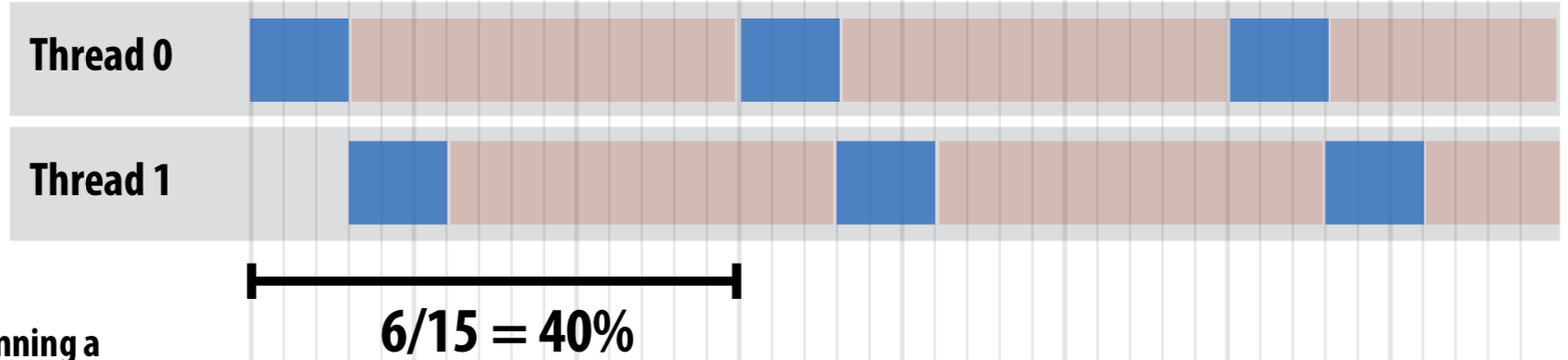
하나의 코어에서 3개의 arithmetic instructions와 12 cycle이 걸리는 memory load를 반복하는 프로세스가 있다고 가정하자. 하나의 스레드에서는 아래와 같이 수행될 것이다.

이러한 경우 CPU의 utilization은 3/15=20% 밖에 되지 않는다. 2개의 스레드가 있으면 아래와 같다.
5개의 thread가 있다면 CPU utilization을 100%가 되고 thread를 더 늘린다고 더 나은 성능을 기대하기는 어렵다. CPU의 utilization을 100%로 이끌기 위한 thread의 수, thread 는 아래와 같다.
multi-threading 을 하드웨어 단에서도 지원해준다 (Hardware-supported multi-threading). 이는 아래와 같은 특징이 있다.
- core가 multiple threads의 수행을 결정한다.
하나의 core는 제한된 ALUs를 가지므로 thread의 어떤 instruction을 수행할지 결정해야한다.
- Interleaved multi-threading (a.k.a. temporal multi-threading)
번갈아가면서 서로 다른 thread를 수행 (기본적으로 알고 있는 threading 이라고 생각)
- Simultaneous multi-threading (SMT)
각 clock 에서 core는 여러 개의 thread 중 어떤 instruction을 수행할지 결정한다.
Example:
Intel Hyper-threading(2 thread per core)
정리하자면, modern parallel processors를 효율적으로 사용하기 위해선 어플리케이션은,
- 모든 execution units를 사용하기 위해 충분한 parallel task가 있어야한다.
- 모든 parallel tasks 들은 같은 sequence of instructions로 수행되도록 한다. (SIMD 활용 위함.)
- ALUs의 총 수보다 더 많은 parallel tasks를 나누어 놓아야함. 그래야 하나의 core에서 여러 thread를 번갈아 가며 수행하며 (interleave) stall을 숨길 수 있기 때문이다.
Memory Bandwidth
Memory bandwidth: 메모리 시스템이 프로세서에 데이터를 전달할 수 있는 rate (e.g. 20GB/sec)

throughput은 memory latency나 너무나 많은 memory requests에 따라 생길 수 있지만, 해결이 가능하다. throughput을 제한하는 유일한 원인은 바로 memory bandwidth이다.
Take Home
- 하나의 processor 에서의 multiple threads는 어떤 thread에서 stall이 되면 그냥 다른 thread를 수행함으로써 stall을 피할 수 있다.
하지만, 이것으로 stall을 없애는 것이 아니라, 단지 stall을 숨기는 것이라는 것을 기억해야한다.
- multi-threads를 수행하는 processor는 다른 스레드의 arithmetic instructions를 수행함으로 stall을 숨긴다. 즉, 제한된 리소스에서 memory access를 최소화하는 것이 중요하다.
- 컴퓨터의 성능 제한은 memory bandwidth 에
critically dependent하다. 바로 이 memory bandwidth의 제한을 극복하는 것이 modern software engineers의 숙명이다.
끝.
Uploaded by N2T