본 포스팅은 Stanford Univ. 의 CS149 2022 fall 수업을 정리한 내용임을 밝힙니다.
From smart phones, to multi-core CPUs and GPUs, to the world's largest supercomputers and web sites, parallel processing is ubiquitous in modern computing. The goal of this course is to provide a deep understanding of the fundamental principles and engineering trade-offs involved in designing modern parallel computing systems as well as to teach parallel programming techniques necessary to effectively utilize these machines. Because writing good parallel programs requires an understanding of key machine performance characteristics, this course will cover both parallel hardware and software design.
https://gfxcourses.stanford.edu/cs149/fall22/courseinfo
Goal
한 번에 많은 프로세싱 elements 를 돌려서 성능 향상을 얻는 것이 병렬 프로그램의 목적.
위와 같은 문제를 설정하고 을 최대로 하는 것이 목표.
프로세스의 갯수 와 이 비례하다면 이를 scalable 하다고 하다.
Observations from demos
-
Communicationlimited the maximum speedup achieve→ 따라서 communication 시간을 줄이면 성능이 자연스레 오른다.
Imbalancein work limited the maximum speedup achiev→ task 를 잘 배분하면 성능이 오른다.
Communication이 정말정말 dominant 한 성능 저하 요소 이다.
Course Themes
- Tasks 를 잘 나누고 이 사이의 communication 시간을 줄여라
- 코드를 디자인 하는데 있어 abstraction 을 잘해라. (좋은 코드는 읽기 좋은 코드)
Fast ≠ Efficiency.efficiency도 충분히 고려해라.
Instruction level parallelism (ILP) example
ILP- 한 번에 병렬 처리할 수 있는 instructions 을 구분하기 위한 level value.

위와 같은 예제가 있다고 하자. 총 5개의 instructions 로 이루어져있음.
이를 프로세스 2개, 3개로 수행하여보자.


💡
2, 3개의 프로세서를 갖는 프로세서가 모두 3 clocks 걸려 instructions 를 수행함.

- ILP 를 계산하여 같은 ILP를 갖는 연산들은 한 번에 같이 수행할 수 있지만 그렇지 않으면 기다려야한다.
Superscalar execution
- 서로 독립적인 instructions 를 자동으로 찾아서 이를 multi-processes 에 잘 배분하여 수행함.
out-of-order process가 따로 있음. (병렬 처리를 자동으로 해주는 전처리기)
- Intel 의 CPU, 펜티엄 4 를 기준으로 ILP를 적용해도 성능의 향상에 한계가 있음.
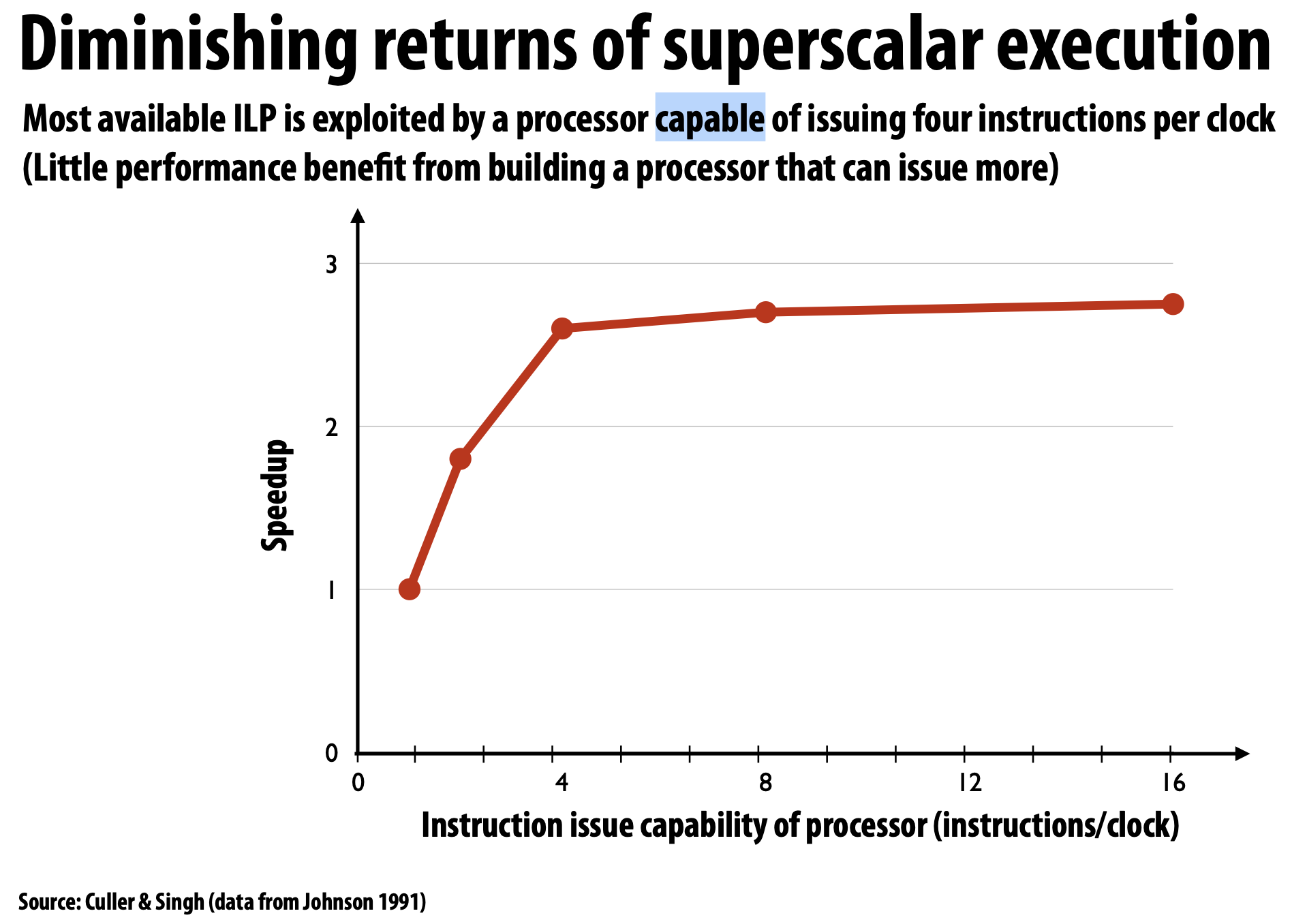
- 성능 ILP가 성능 향상을 가져오지 않음.

하드웨어의 성능 향상으로 인한 소프트웨어 성능 향상은 끝났다.
- CPU의 클럭은 파워 때문에 제한됨.
- ILP 의 scaling 도 한계에 다다름.
💡
Software must be written to be parallel to see performance gains. No more free lunch for software developers!
Take Home
💡
하드웨어 단에서 자동으로 parallelization 해서 성능을 향상 시키는 것과 싱글 코어를 고문해서 얻는 성능 향상은 한계에 다다름.
프로그래머가 parallelism 한 코드를 “명시적으로” 작성해야한다.
Uploaded by N2T