본 포스팅은 Stanford Univ. 의 CS149 2022 fall 수업을 정리한 내용임을 밝힙니다.
 https://github.com/stanford-cs149/asst1#program-1-parallel-fractal-generation-using-threads-20-points
https://github.com/stanford-cs149/asst1#program-1-parallel-fractal-generation-using-threads-20-points1. Program 1: Parallel Fractal Generation Using Threads (20 points)
prog1_mandelbrot_threads/ 아래 있는 코드들들 빌드하고 수행한다. make로 빌드하고 ./mandelbrot 으로 실행하면된다. 프로그램을 수행시키면 mandelbrot-serial.ppm 이라는 파일이 생성되는데 이는 유명한 complex 수의 집합인 Mandelbrot set을 형상화한 이미지임.

위와 같은 이미지가 보인다면 잘 수행시킨 것이며, 이미지의 각 픽셀은 복소평면 상의 값에 대응되며 픽셀의 밝기 값은 연상 수행량에 비례하며, 이 값은 해당 값이 Mandelbrot의 집합에 포함되는지 안되는지를 결정하는 값임.
본 과제에서 우리가 할 일은 std::thread를 이용해서 이러한 연산을 parallelize하는 것임. 스레드 하나를 spawn하는 Starter code는 manedlbrotThread.cpp 코드의 mandelbrotThread() 함수에 작성돼있다. 이 함수에서 메인 스레드는 constructor, std::thread(function, args…) 함수를 사용하여 추가적인 스레드를 수행시킨다. 그리고 수행시킨 스레드들이 종료될 때까지 join() 함수에서 이들을 기다린다.
workerThreadStart 함수에 코드를 추가하여 병렬 연산을 수행하는 것이 본 과제의 목표임.
- What you need to do
- 2개의 프로세스를 사용하여 코드를 병렬처리하도록 코드를 수정. 이미지를 위, 아래로 나누어 윗부분은 threa0가, 아랫 부분은 threa1이 처리하도록 코드를 작성한다. 이렇게 나누어 병렬 처리하는 것 (decomposition) 을 spatial desomposition 이라고 한다.
typedef struct { float x0, x1; float y0, y1; unsigned int width; unsigned int height; int maxIterations; int* output; int threadId; int numThreads; // added by joono int startRow; int totalRow; } WorkerArgs; ===================================== // mandelbrotThread 함수 안에서 수정 // static work allocation args[i].totalRow = height / numThreads; args[i].startRow = i * (height / numThreads);
- 2배의 성능 향상
- 이미지를 더 잘게 나누어 코드의 thread를 3, 4, 5, 6, 7, 8 로 증가시켜서 수행시킨다. (스탠포드 학생들이 지원받은 서버의 스펙으로는) 4개의 프로세스가 있고 각 프로세스는 2개의 hyper-threads를 지원하기 떄문에 개 까지는 쌓아올릴 수 있다.
이 과정에서 성능이 얼마나 향상되는지, 그래프를 그려 이를 serial 하게 수행한 결과와 비교한다. 성능이 linear하게 향상 되는가? Scalable한가? 그렇다면 왜 그런지에 대한 설명을 하라.
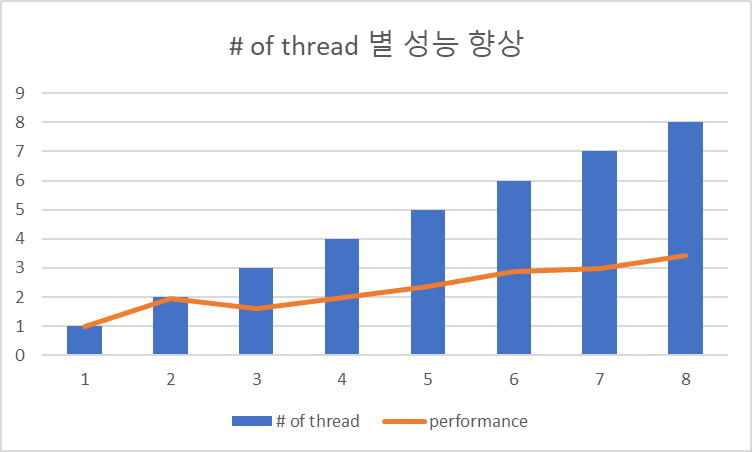
- 성능이 thread가 많아질 수록 증가는 하지만 성능 향상이 linear 하지 않음.
- 가설: 각 thread가 할 일의 총량이 다름. 이를 맞춰줘야 제대로 병렬처리가 될 것.
- 2.에서 세운 가설이 타당한지를 판단하기 위해 각 thread의 수행 시간을 측정한다.
workerThreadStarter()함수의 처음과 끝에 시간을 재는 코드를 추가하면 된다.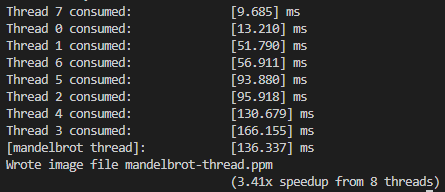
- 8개의 thread로 수행했을 때의 각 thread 별 수행 시간이 천차만별인 것을 확인할 수 있음. thread7은 9.6ms 가 소요됐지만, thread3은 136.3ms가 소요됐다. 약 14배 이상의 수행 시간차이가 생긴 것이다. 이미지가 생성되기 위해서는 모든 스레드가 task를 마쳐야 하므로 가장 수행 시간이 긴 thread가 bottleneck을 형성.
따라서 모든 thread가 비슷한 양의 task를 받아 수행하도록 work mapping policy를 구현하면됨.
- 8개의 thread로 수행했을 때의 각 thread 별 수행 시간이 천차만별인 것을 확인할 수 있음. thread7은 9.6ms 가 소요됐지만, thread3은 136.3ms가 소요됐다. 약 14배 이상의 수행 시간차이가 생긴 것이다. 이미지가 생성되기 위해서는 모든 스레드가 task를 마쳐야 하므로 가장 수행 시간이 긴 thread가 bottleneck을 형성.
- task를 각 thread에 mapping하는 것을 수정하여 성능을 7-8배까지 증가시켜라. 스레드 간의 어떤 synchronization도 필요하지 않고 task를 나누는 하나의 간단한 policy로도 충분히 7-8배의 성능 향상을 기대할 수 있음. (하드 코딩은 허락하지 않음.)
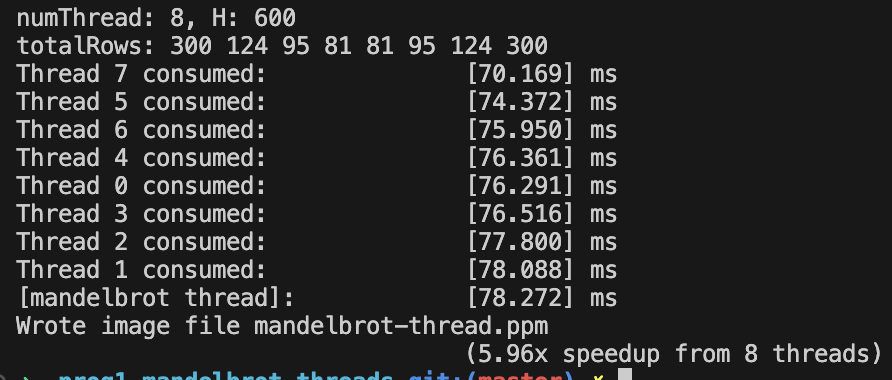
- 3. 문제에의 결과, static assignment, 에서 각 스레드가 수행되는 평균 시간은 약 76.62ms 임. 이 평균 값은 수행 가능한 optimal한 퍼포먼스라고 볼 수 있음. 4. 문제에서 구현한 dynamic assignment 에서 가장 오래 수행된 스레드가 78.125ms 이다. 따라서 2ms 정도의 오버헤드를 제외하고 거의 optimal 한 결과를 얻었다고 볼 수 있다.
- 마지막으로 너의 코드를 16 스레드에서 수행키셔보고 성능이 향상됐는지를 판단하라.
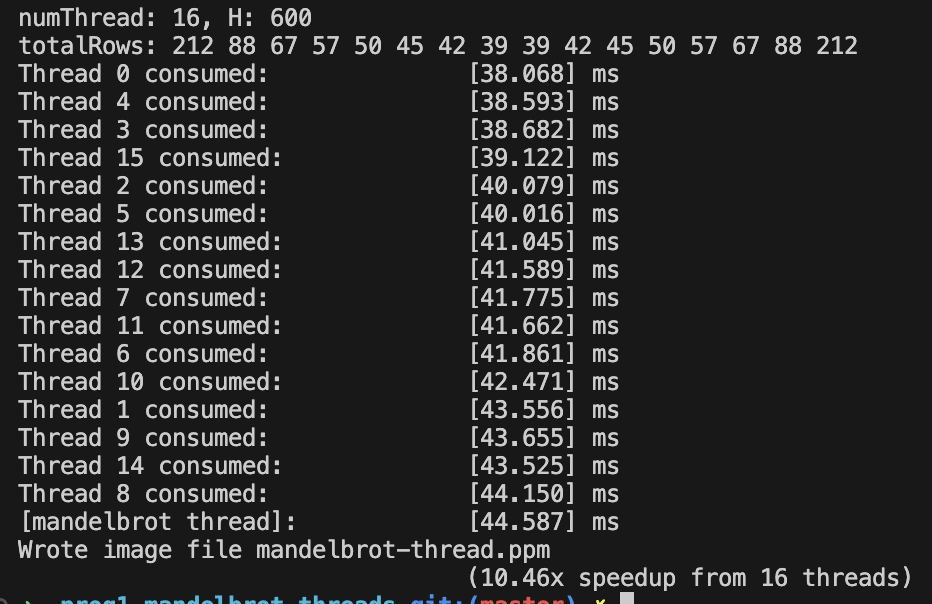
- 8개의 스레드를 사용했을 때의 성능과 16개의 스레드를 사용했을 때의 성능이 2배 증가하였다. 성능이 잘 향상되었다.
- 2개의 프로세스를 사용하여 코드를 병렬처리하도록 코드를 수정. 이미지를 위, 아래로 나누어 윗부분은 threa0가, 아랫 부분은 threa1이 처리하도록 코드를 작성한다. 이렇게 나누어 병렬 처리하는 것 (decomposition) 을 spatial desomposition 이라고 한다.
Uploaded by N2T