본 포스팅은 Simon J.D. Prince 의 Deep Learning 교재를 스터디하며 정리한 글임을 밝힙니다.
1. Introduction
Artificial Intelligence: 인지 행동을 모방하는 시스템을 구축하는 학문
Machine Learning: 주어진 데이터를 통해 수학적인 모델을 fitting 하여 결정하고록 하는 것을 학습하는 AI의 subset.
Deep Neural Network: ML 모델 중에서도 크고 거대한 모델들을 의미함. 앞으로 스터디 하는 동안 다룰 토픽.
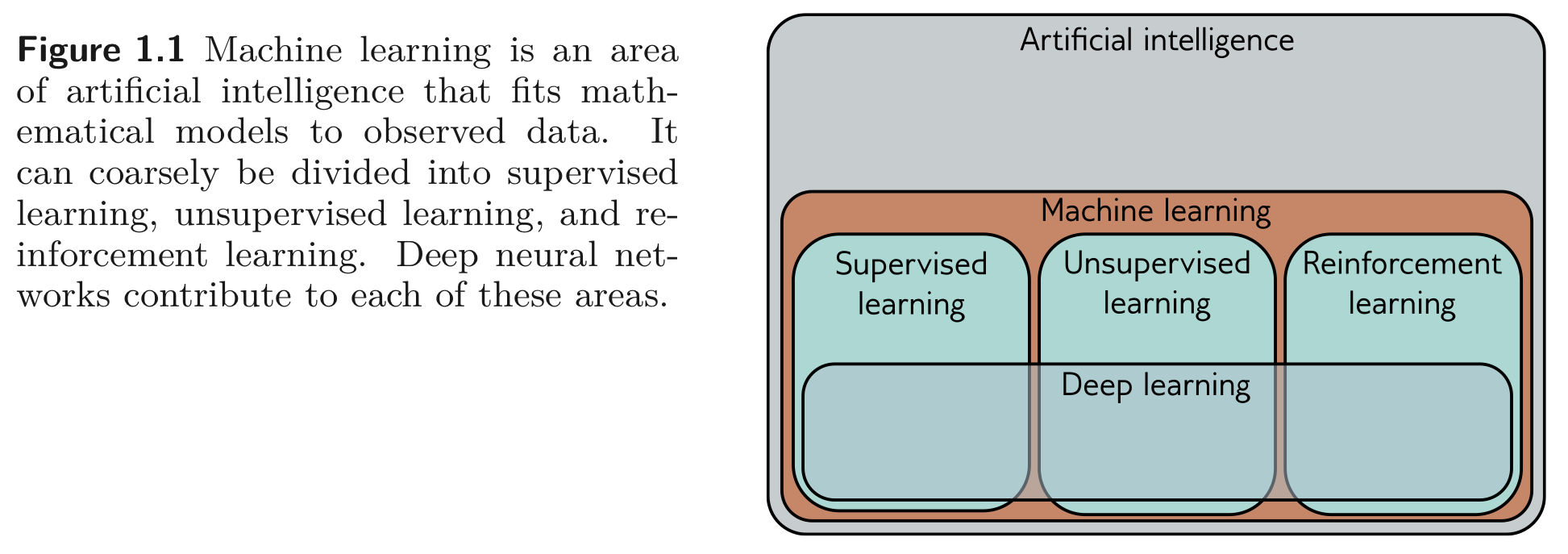
- ML은 크게 3가지의 파트로 구분할 수 있다.
- Supervised learning
- Unsupervised learning
- Reinforcement learning
1.1. Supervised Learning
Supervised learning model 은 input data 로부터 output data 로의 mapping 을 정의한다.
1.1.1. Regression and classificatino problems
먼저 input, output data는 보통(거의 모두) vector format 으로 encoding, decoding 된다. 아래 설명에서는 아직은 ML model 을 blackbox 로 여기고 설명을 진행한다.
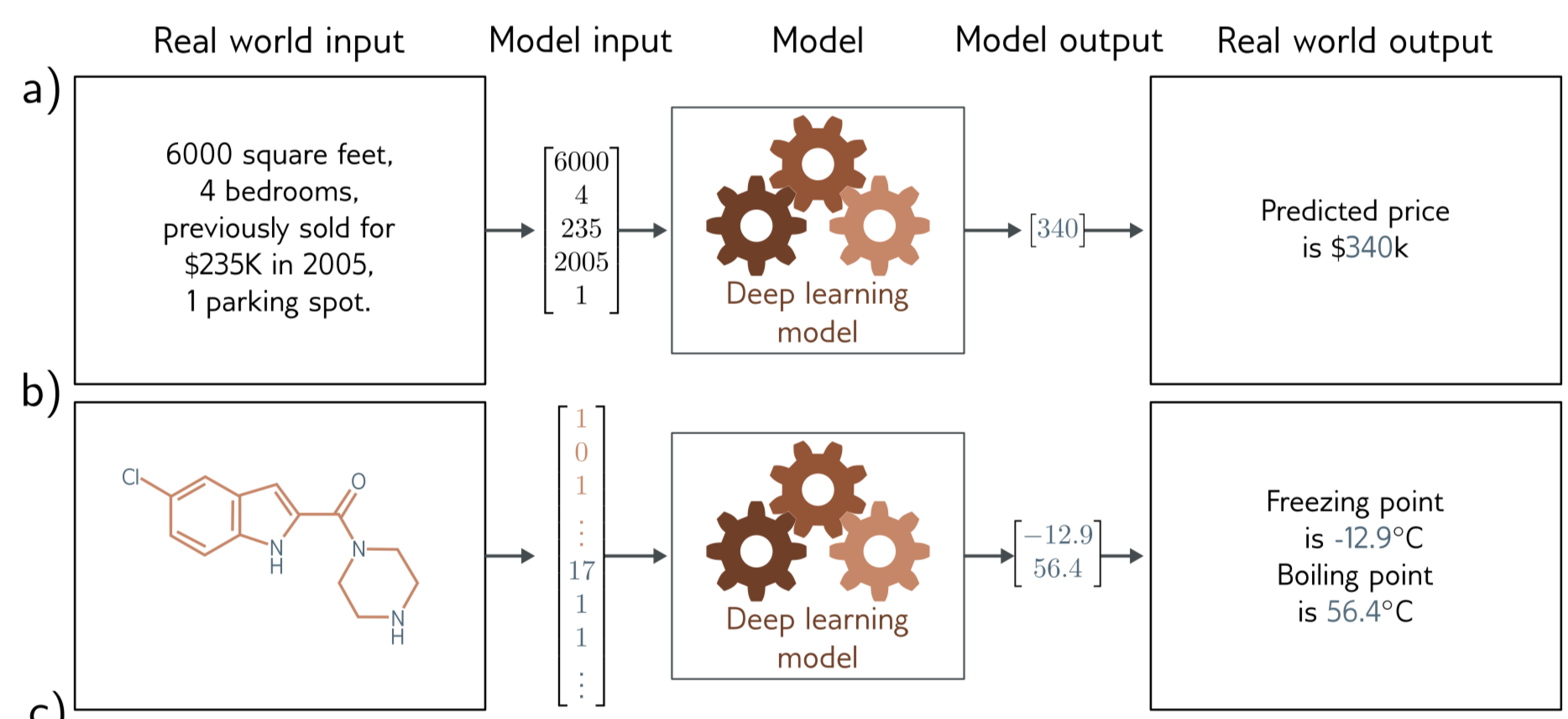
위 a-b) 의 예제는 Regression task 의 예시를 보인다. 방의 정보, 혹은 분자의 구조에 대한 정보가 vector format 으로 주어졌을 때 이에 대한 결과로 방의 가격, 어는 점, 끓는 점에 대한 어떤 continuous number 로 return 된다.
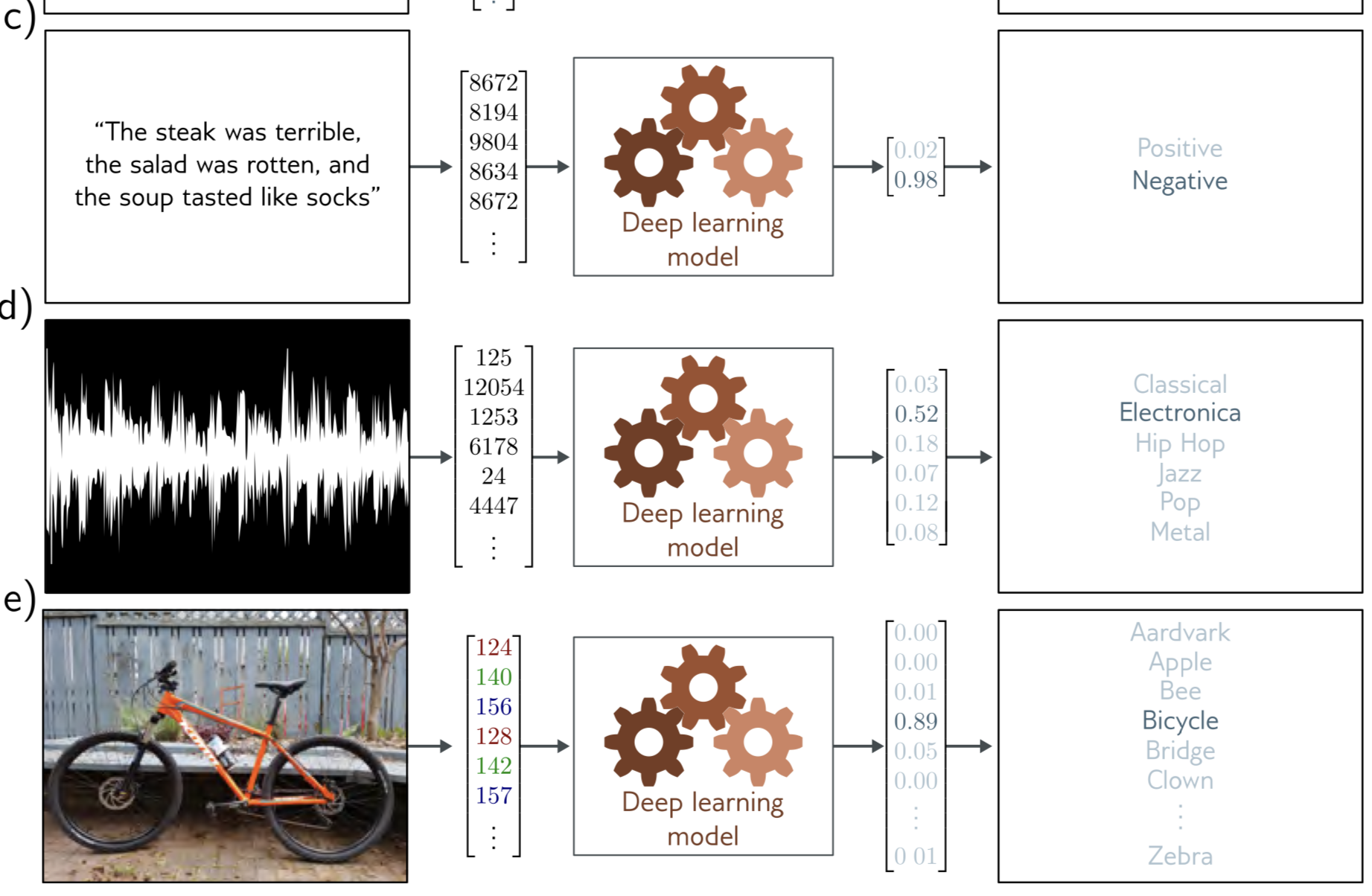
c-e)는 반면 어떤 category 를 결과로 낸다. 이를 Classification task라고 한다.
1.1.2. Inputs
input도 다양한 form 을 갖는다. 예를 들어 집 값에 대한 정보는 순서가 있고 길이가 고정 돼있다. 이러한 데이터를 Structured or tabular data 라고 한다.
반면, 레스토랑 리뷰 같은 text 같은 경우 길이가 문장의 단어의 갯수에 따라 다르기 때문에 variable 하고 특히 순서가 중요하다.
sound data 의 경우는 약 10초 정도로 소리를 끊었을 때, 약 441,000개의 정수값을 갖는다. 이미지의 경우 2D 픽셀 값들로 구성되어 있고, 각 픽셀 간은 서로 매우 밀접하게 연관 돼있다. 분자 구조를 분석하는 데이터의 경우는 분자 구조를 vector form 으로 변환하기 위해 특별히 고안된 모델의 구조가 필요하다.
1.1.3. Machine learning models
예제를 살펴보자.
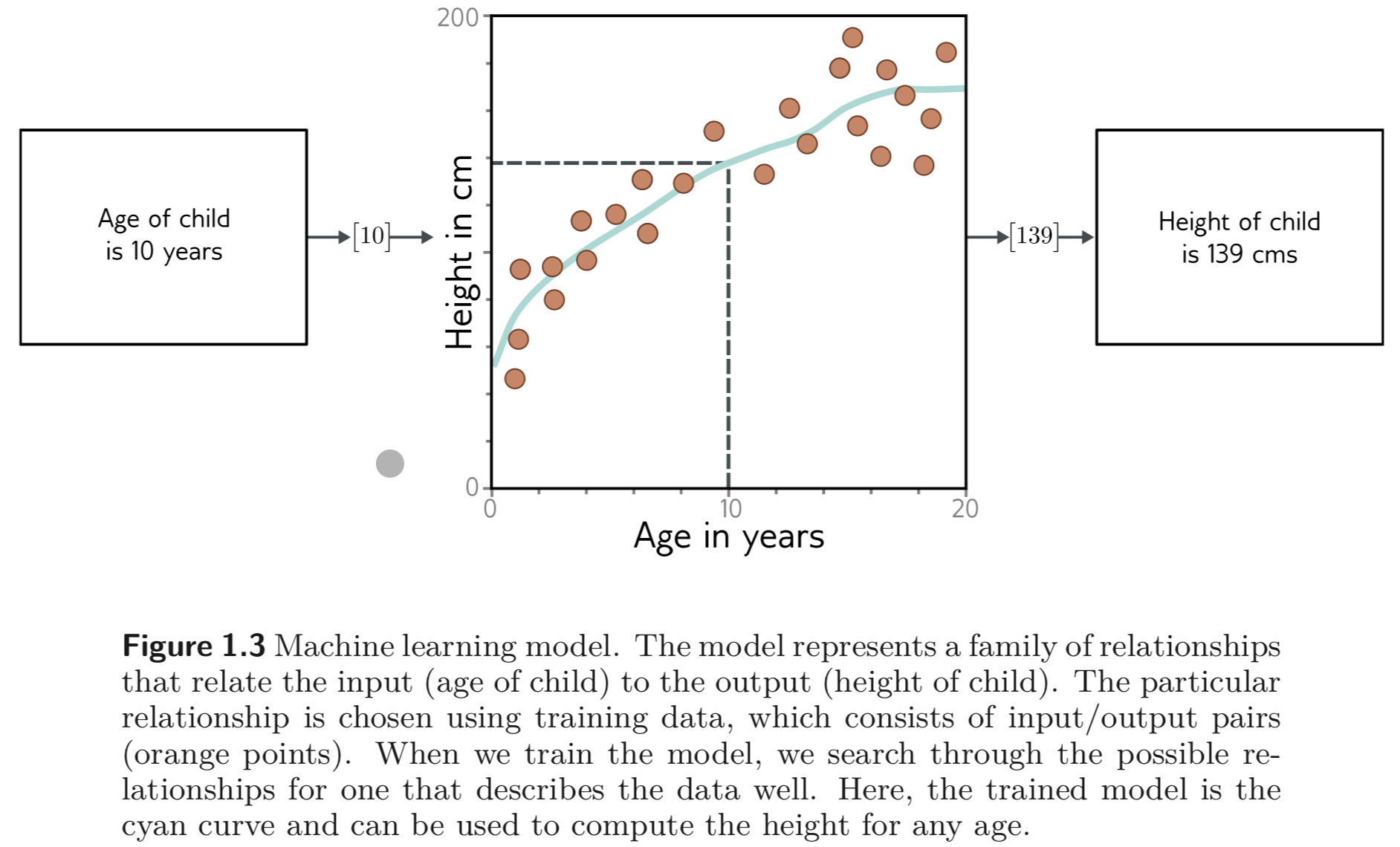
ML model 은 나이에 따라 평균 키가 어떻게 변하는지를 나타내는 수학적인 방정식이다. 구체적으로, input 을 output으로 mapping 하는 family of equations 을 나타낸다. (청록색 라인)
청록색 라인을 만들기 위해 우리는 training data (input/output pairs) 를 사용한다. (주황색 점들) training 혹은 fitting 이라고 하는 작업은 이러한 데이터들을 가장 정확하게 표현하는 어떤 family of equations 를 찾는 것이다.
위와 같이 input/output pairs 는 training process 에서 teacher 혹은 supervisor 의 역할을 하며 따라서 supervised learning 이라는 이름이 붙었다.
1.1.4. Deep Neural Networks
생략. 위와 같은 ML model을 다양한 input/output 에 대하여 사용하며, 크고 깊은 모델이 필요하다고 함. 원론적인 얘기
1.1.5. Structured Outputs
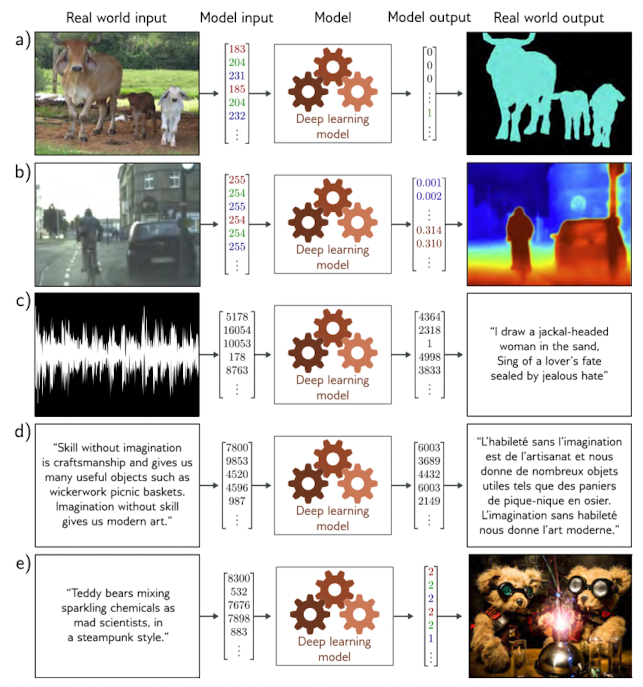
앞서 간단한 regression, classificaion 과는 달리, 위 figure 에서 순차적으로, semantic segmentation, depth map estimation, sound2text, translation, text2img tasks 와 같은 sturctured outputs을 갖는 tasks가 있다.
sound2text, translation, text2img 와 같은 tasks 들은 보통 일반적인 supervised learning 으로 위 tasks를 해결할 수 있지만 아래와 같은 2가지의 이유로 보통 더 어려운 tasks로 여겨진다.
- output 이 보통 모호함, 여러 가지 답이 있을 수 있음. (ambiguous)
- output 이 어떤 특정한 구조 를 가질 수 있음.
- 문장의 경우 “문법”에 맞게 생성되어야 하며, 이미지의 경우도 손가락이 6개거나 엄지와 검지가 연결되어 있는 등의 비정상적인 이미지를 생성 해서는 안된다.
“문법”의 경우 많은 양의 text로 부터 어떤 규칙들(statistics) 을 배울 수 있다. 뒤에 나오는 unsupervised learning 과 연결된다.
1.2. Unsupervised Learning
input 데이터만 있고 output 데이터가 없는 데이터로부터 모델을 구축하는 것을 unsupervised learning 이라고 한다. Unsupervied learning 의 목표는 data의 구조를 나타내고 이해하는 것이다.
1.2.1. Generative Models
본 교재에서는 generative unsupervised model 에 초점을 맞춤.

Figure 1.5 는 이미지 생성 모델의 예시이며, Figure 1.6 은 text 생성 모델의 예시이다.


Figure 1.7, 1.8 은 각각 image inpainting, text completion 이며 완전히 아무것도 없는 것에서 생성하는 것이 아니라 조건에 맞추어 생성하는 것이므로 를 conditional generation 이라고 한다.
1.2.2. Latent Variables
많은 generative model 들은 주어진 데이터가 갖는 생 숫자 (raw number)들 보다 작은 차원으로 표현될 수 있다고 알려져 있는 바 (observation)를 이용 (exploit) 한다. 예를 들어 무작위로 생성한 영어 알파벳들 중 의미가 있는 영어 문장은 아주 극소수 일 것이다. 마찬가지로 RGB 이미지에서도 각 픽셀의 값이 무작위로 있다고 했을 때 그 중에 의미 있는 이미지도 역시 극소수일 것이다.
위와 같은 아이디어를 통해 우리는 주어진 데이터들을 작은 수, 차원을 갖는 latent variables 로 표현한다.
여기서 DL model의 역할은 이 latent variables 와 data 간의 mapping을 나타내는 것이다.
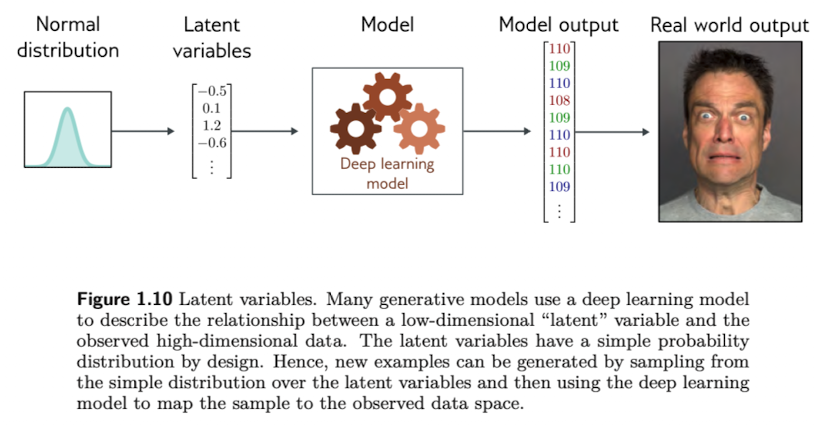
보통 latent variables 로 normal distribution 에서 sampling 한 값들을 사용한다. latent variable 과 데이터 간의 관계가 학습이 되면 이를 통해 interpolation 도 할 수 있다.

1.2.3. Connecting Supervised and Unsuperviced Learning
latent variables 를 이용한 generative model 은 structured output 을 갖는 task 에서 supervised learning 에도 잘 사용될 수 있다.
예를 들어, text input 과 image output 을 곧장 mapping 하는 함수를 설계하기 보다 둘의 관계를 잘 설명하는 text를 나타내는 latent variables와 이미지를 나타내는 latent variables를 학습하는 것이 더 좋은 결과를 낼 수 있다.
이러한 방법은 아래와 같은 3가지의 장점이 있다.
- text와 이미지가 lower dimension에 mapping 되므로 적은 pairs의 데이터셋으로도 학습할 수 있다.
- 더 좋은 (plausible-looking) 결과를 생성할 수 있다.
- 만약 각각의 latent variables 사이나 latent variables 에서 이미지를 생성하는 것에 randomness 를 추가할 수 있다면 다양한 (diverse) 결과를 생성 할 수 있다.

1.3. Reinforcement Learning
강화학습은 어떤 agent 가 어떤 world 에 살아서 특정한 action 을 주어진 time step 에 취하는 패러다임을 제안한다. Agent가 어떤 action을 취하면 그 action에 따른 rewards와 다음 state를 얻는다.
강화학습의 목표는 agent 가 높은 보상을 받도록 다음 action을 취하도록 하는 것이다.
하지만 reward가 당장의 action으로 주어지지 않는 경우가 있다 (e.g. 바둑, 체스 등등). 이럴 때는 어떠한 action이 reward에 영향을 미치는지 알기 어려운데 이러한 문제를 temporal credit assignment problem 이라고 한다. 또한 자신이 학습한 것이 최선의 방법인지, 따라서 학습한 대로 action을 취해야할지 모험을 할지 결정해야한다. 따라서 강화학습에서는 exploration 과 exploitation 사이의 trade off 를 잘 정하는 것이 중요하다.
1.4.-6. Ethics, etc..
생략
2. Supervised Learning
Supervised learning model은 하나 이상의 input 으로부터 하나 이상의 output 으로의 mapping 을 정의한다. 이러한 모델은 수학적인 방정식이며, input이 주어지면 output을 그냥 방정식대로 “계산”하는데 이를 inference 라고 한다. 이러한 방정식을 구성하는 값들을 parameters 라고 한다.
모델을 training, fitting 혹은 learning 은 주어진 학습 데이터 간의 관계를 가장 잘 나타내는 parameters 를 찾는 것이다.
2.1. Supervised learning overview
본 섹션에서는 input vector x 를 입력받아 prediction y 를 출력하는 모델을 build 하는 것임.
예시로 자동차 가격을 예측하는 모델을 구축하기 위해 x 는 [연식,주행거리] 의 형식을 갖는다고 하자. 이렇게 정해진 길이와 정해진 순서를 갖는 데이터를 tabular data 라고 한다.
Prediction을 하기 위해 모델, f[∙]를 아래와 같이 정의한다.
여기서 모델은 parameters를 포함하기 때문에 parameters를 ϕ 로 나타내고 식을 아래와 같이 다시 쓸 수 있다.
training 혹은 learning 은 input 으로 부터 납득할만한 output을 내도록 하는 parameter, ϕ를 찾는 것이다. 이를 위해 training data, {xi,yi}i=1,2,...,I가 필요하고 training data의 input 과 이에 대응하는 output을 가능한한 잘 설명하는 ϕ를 찾아야한다.
이를 위해 현재의 ϕ 가 얼마나 못하는지 (mismatch) 에 대한 정도를 나타내야하는데 이를 loss, L 이라고 한다. 우리가 하는 일을 다음과 같이 식으로 나타낼 수 있다.
loss가 충분히 작아진다면 우리는 input, xi가 주어졌을 때 이에 대응하는 output yi 를 prediction할 수 있다. 학습이 끝난 후, 학습된 모델이 얼마나 잘 하는지 (performance), 또한 얼마나 잘 일반화 되었는지 (generalization) 확인하는데 이를 학습에 사용되지 않은 test data 로 해야한다.
2.2. Linear Regression Example
scalar x,y 가 주어졌을 때 이를 예측하는 모델을 만드는 예제를 공부한다.
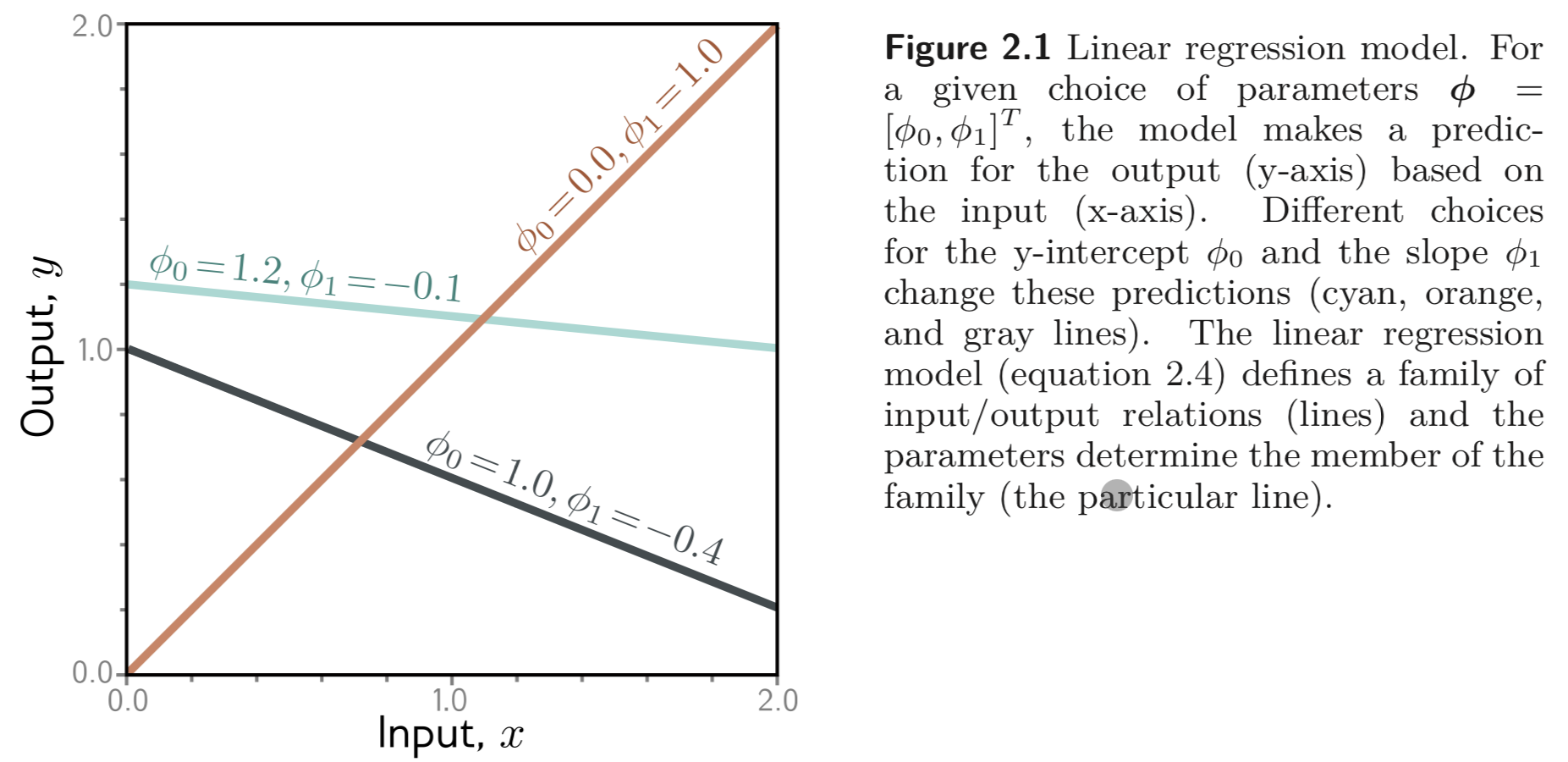
- 1D Linear Regression Model
1D linear regression model 은 x,y 간의 관계를 아래와 같이 나타낸다.
y=f[x,ϕ]=ϕ0+ϕ1x
ϕ0는 y절편, ϕ1은 기울기를 나타내는 함수라고 볼 수 있고, 아래와 같이 각각의 값이 달라짐에 따라 training data를 나타내는 여러 개의 방정식들 (family of equations) 이 나타날 수 있다.
2.2.2. Loss
학습을 위해서는 parameters ϕ 가 좋은지를 판단할 수 있어야한다. 이를 위해 각각의 parameters 의 값이 결정될 때마다 모델과 데이터 간의 mismatch 한 정도를 나타내는 값을 정의해야하는데 이를 loss 라고 한다.
본 예제에서는 L2 loss 혹은 Least Square loss 라고 불리는 함수를 사용한다. 식은 아래와 같다.
loss function의 목표는 loss 값을 최소화 하는 어떤 ˆϕ 을 찾는 것이다 식으로는 아래와 같이 나타낼 수 있다.
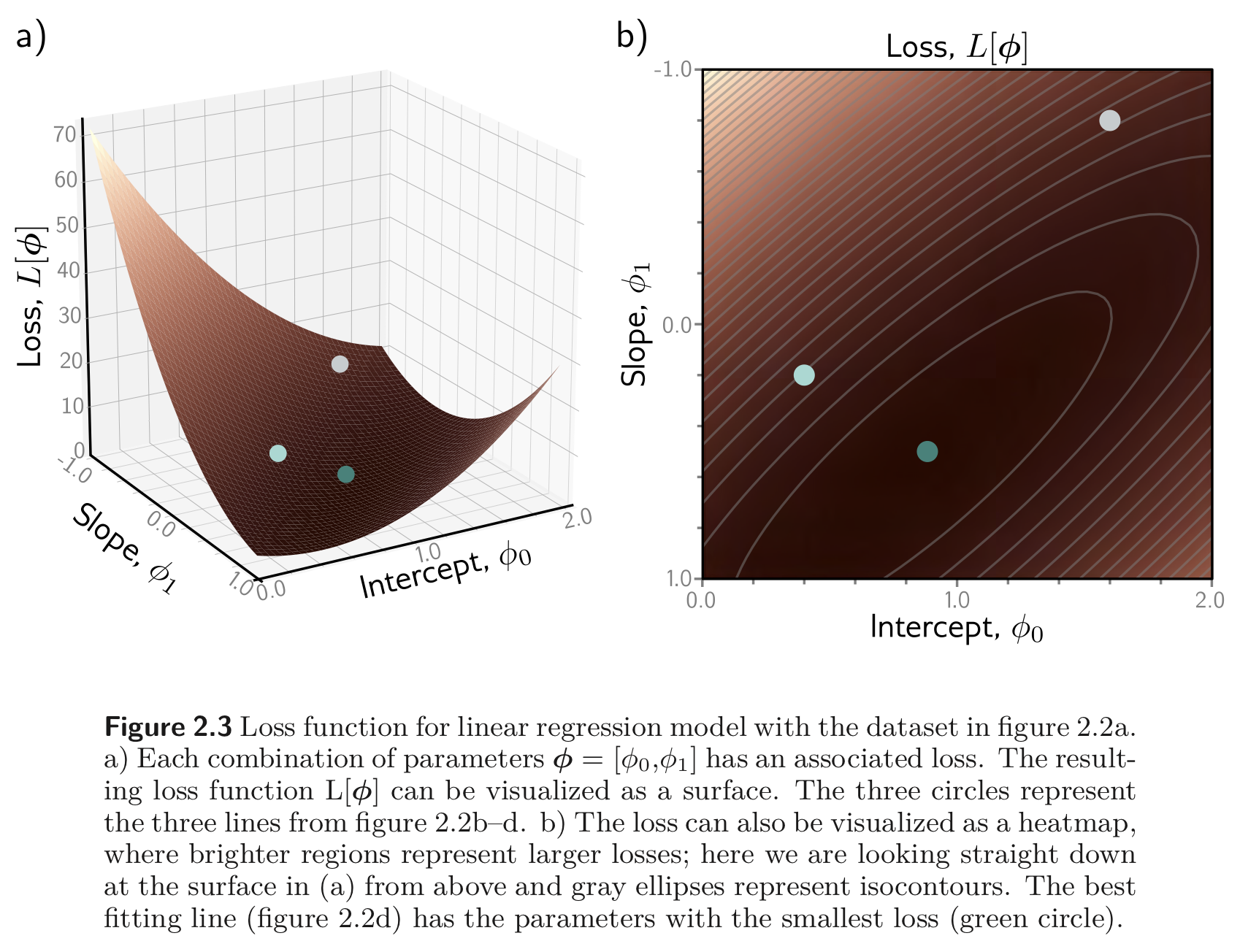
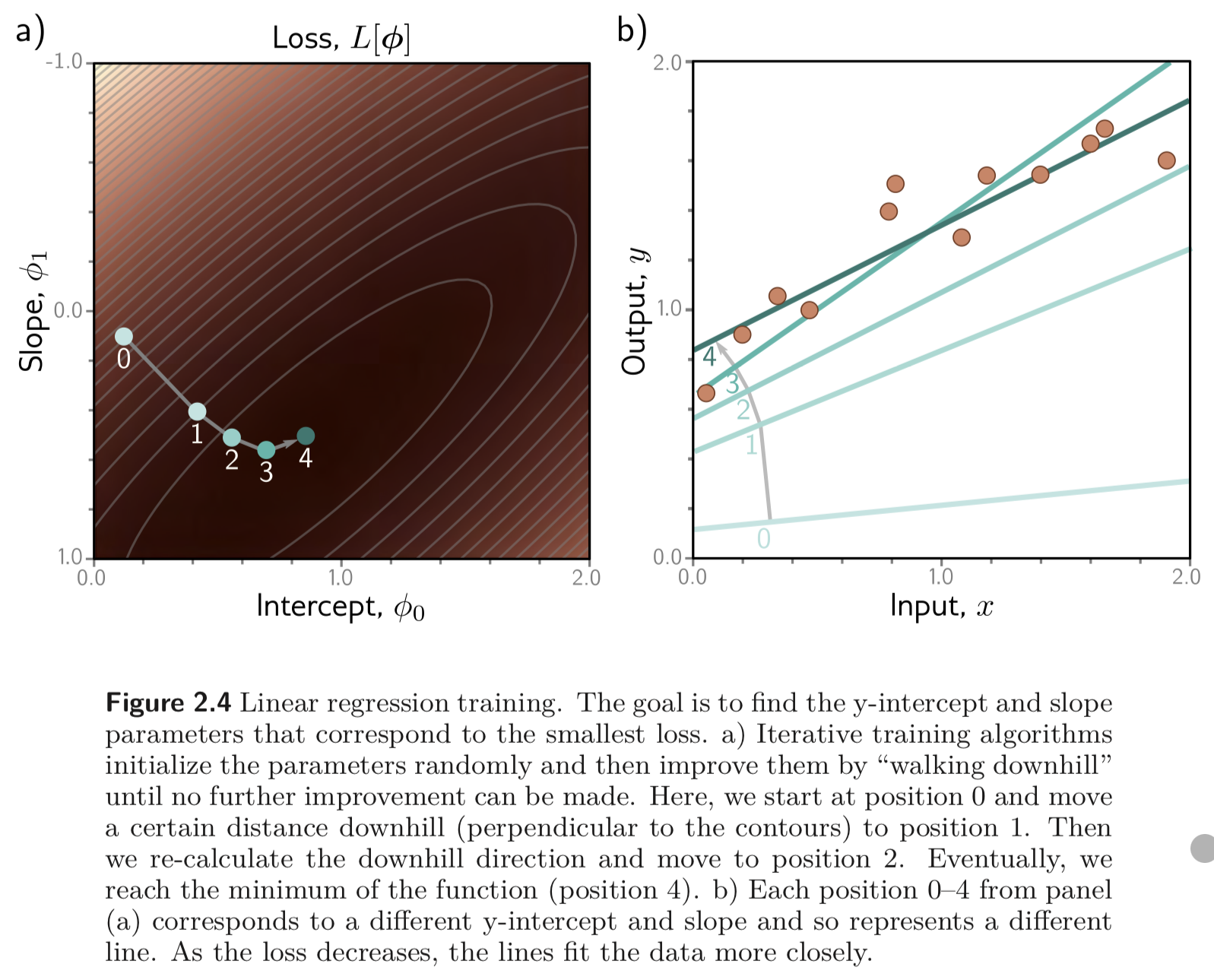
ϕ0,ϕ1 의 조합을 그래프로 나타내고, 각 ϕ 에 대한 loss 값을 그래프로 나타내면 아래와 같이 어떤 slope의 형태로 나타내어질 수 있다.
2.2.3. Training
loss를 최소화하는 파라미터를 찾아가는 process 를 model fitting, training 혹은 learning 이라고 한다.
가장 기본적인 방법은 파라미터를 랜덤으로 설정하고 Figure 2.3 에서 그려진 바와 같이 loss 값을 “Walking down” 하는 방식으로 loss를 최소화 하는 파라미터를 찾아간다.
보통 각 파라미터의 지점에서의 gradient 를 구해 그 반대 방향으로 가면 움푹 패인 곳으로 나아가도록 파라미터를 업데이트 하는 값을 얻을 수 있다 (Gradient Descent). 추후에 공부할 예정.
2.2.4. Test
모델이 충분히 학습되었다고 여겨지면 이를 “테스트” 해봐야한다. 이는 학습에 사용되지 않았던 test data 로 수행한다. 테스트 과정에서 input과 output의 관계를 나타내기에 학습이 부족했거나 모델이 너무 naive 한 경우 성능이 안좋게 나오는데, 이를 underfitting 이라고 한다.
또한 모델이 너무 복잡하여 training data 를 완벽하게 설명하는 모델이 있을 수 있다. 하지만 이런 경우는 보통 training data에는 잘 학습되었으나 잘 일반화 되지 않았다는 표현을 쓰는데 이를 overfitting 이라고 한다.
Problems
Problem 2.1. 예제에서 나타내었던 L2 Loss 의 Gradient 를 ϕ 에 대하여 구하세요
Problem 2.2. 2.1.에서 구했던 미분값을 0으로 두어서 loss를 최소화하는 파라미터 ϕ를 구할 수있는 것을 보여라. 그리고 이를 Closed form(e.g. 공식처럼) 으로 나타내어라.

Problem 2.3*. Linear regression 을 generative model, g 로 만들어 보자. 그리고 g−1 이 기존의 discriminative model, f 와 같은 prediction을 하는지 보여라

x,y 간의 correlation 이 1이라면 slope 에 대해서는 성립. 절편에 대해서는 모르겠다..
Take home
- Machine Learning (ML) 은 Artificial Intelligence (AI) 의 subset 이며 Deep Learning (DL)은 ML 의 subset 이다. 조금 더 구체적으로는 Deep learning은 인간의 행동을 모방하는 기계 (AI)를 수학적 모델로 정의하는데 (ML) 이 수학적 모델이 깊고 파라미터 수가 많은 것을 DL 이라고 한다.
- Deep learning 은 크게 3개의 sections으로 나눌 수 있다. 1) Supervised Learning, 2) Unsupervised Learning, 3) Reinforcement Learning 이다. Supervised Learning 은 training data가 주어졌을 때, input, xi 를 output, yi 에 최대한 잘 맵핑하는 모델을 학습하는 것이 목표이다. Unsupervised learning은 레이블이 없는 데이터 x 가 있을 때, 이 데이터의 구조를 잘 설명하는 것이 목표이다. Reinforcement learning은 agent, state, reward로 구성된 environment가 있을 때 agent가 reward를 최대한 많이 받도록 다음 action을 취하도록 하는 것이다.
- Unsupervised learning 의 경우 데이터의 구조를 학습하기 위해 latent space 를 활용한다. latent space란, “의미 있는 데이터”, (여기서는 학습 데이터, x 가 된다. e.g. 위키 문서, 사진 이미지들) 는 입력 데이터가 가질 수 있는 모든 경우의 수의 극소수일 것이라는 전제로 한다. 따라서 입력 데이터들을 입력 데이터의 dimension 보다 훨씬 작은 dimension을 갖는 latent space에 projection 하는 것.
Uploaded by N2T